
What is activation Function?
Basically it converts all the sum of inputs into output. It’s like a convert machine which helps to describe data with nonlinearity
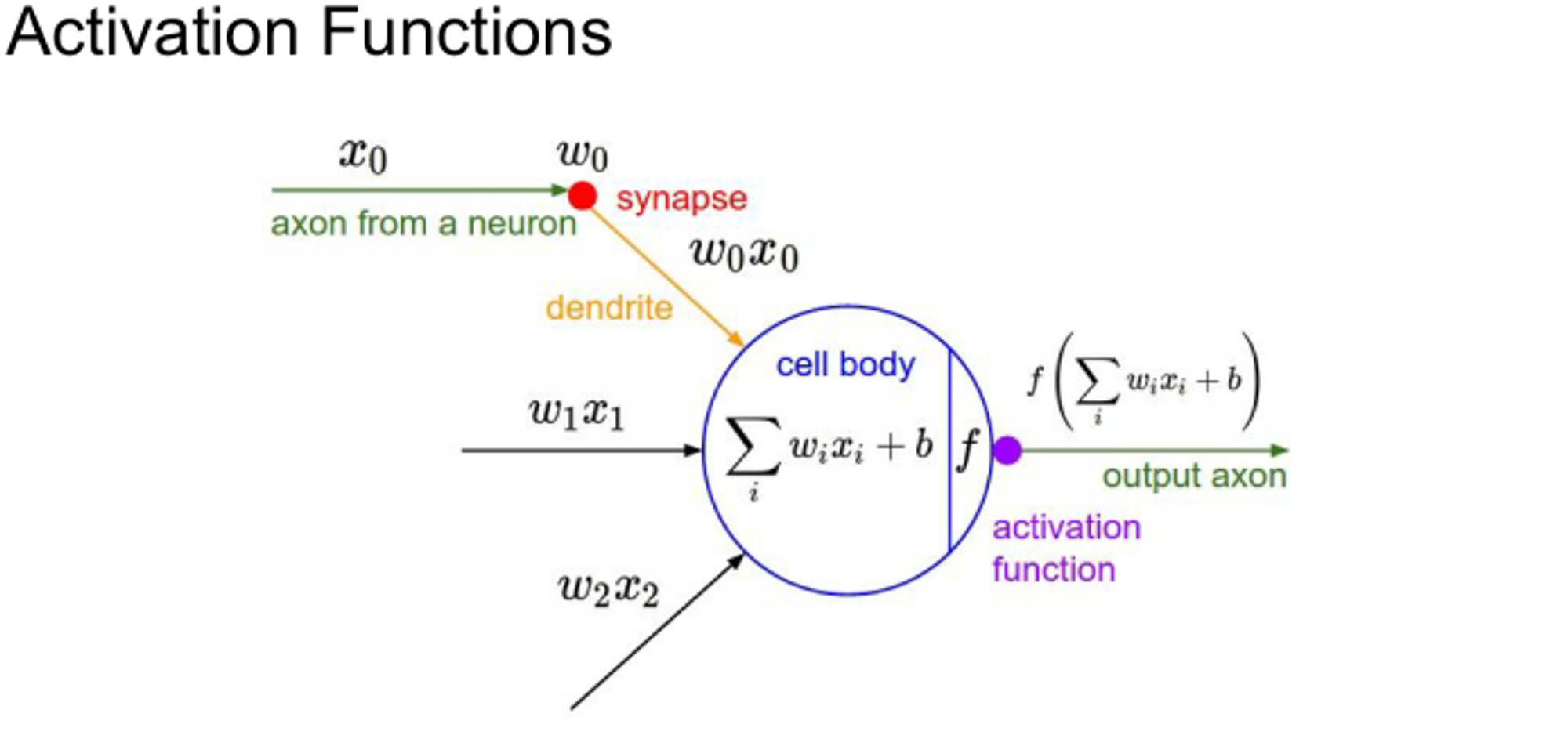
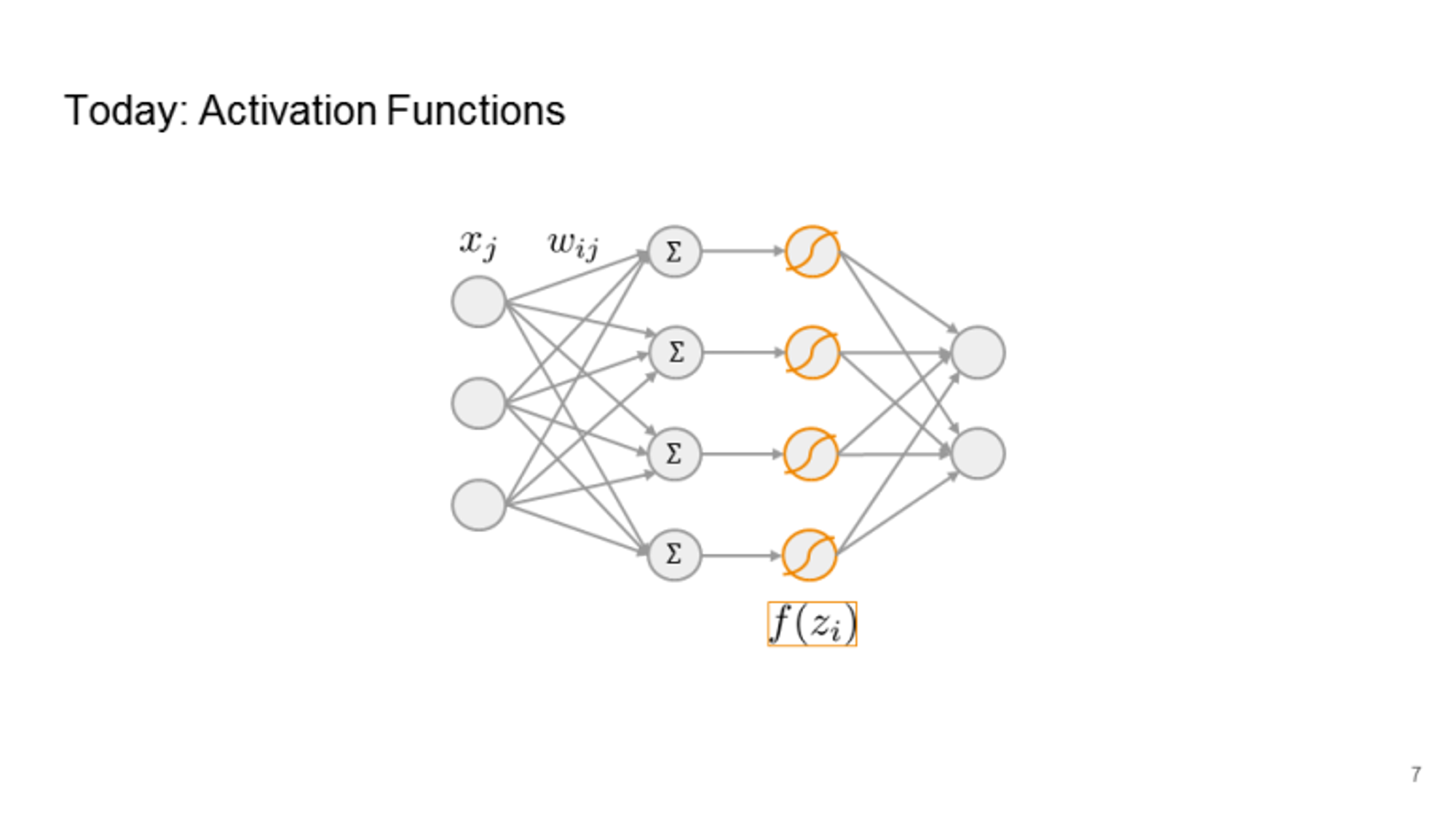
Why do we use it?
It is used to determine the output of neural network like yes or no. It maps the resulting values in between 0 to 1 or -1 to 1 depending upon the function you select to use.
The Nonlinear Activation functions are the most used activation functions that makes easy for the model to generalize or adapt with variety of data and to differentiate between the output.
without Activation func : Linear & Simple Prediction
Linear Activation function : Impossible to execute backpropagation
- when the function is defined as c(x), even though we put bunch of hidden layers on top of each layers, the output will be always c`(x), which is a linear formation.Then there’s no use of using deep neural network.
With Activation func : nonlinear & complex prediction available
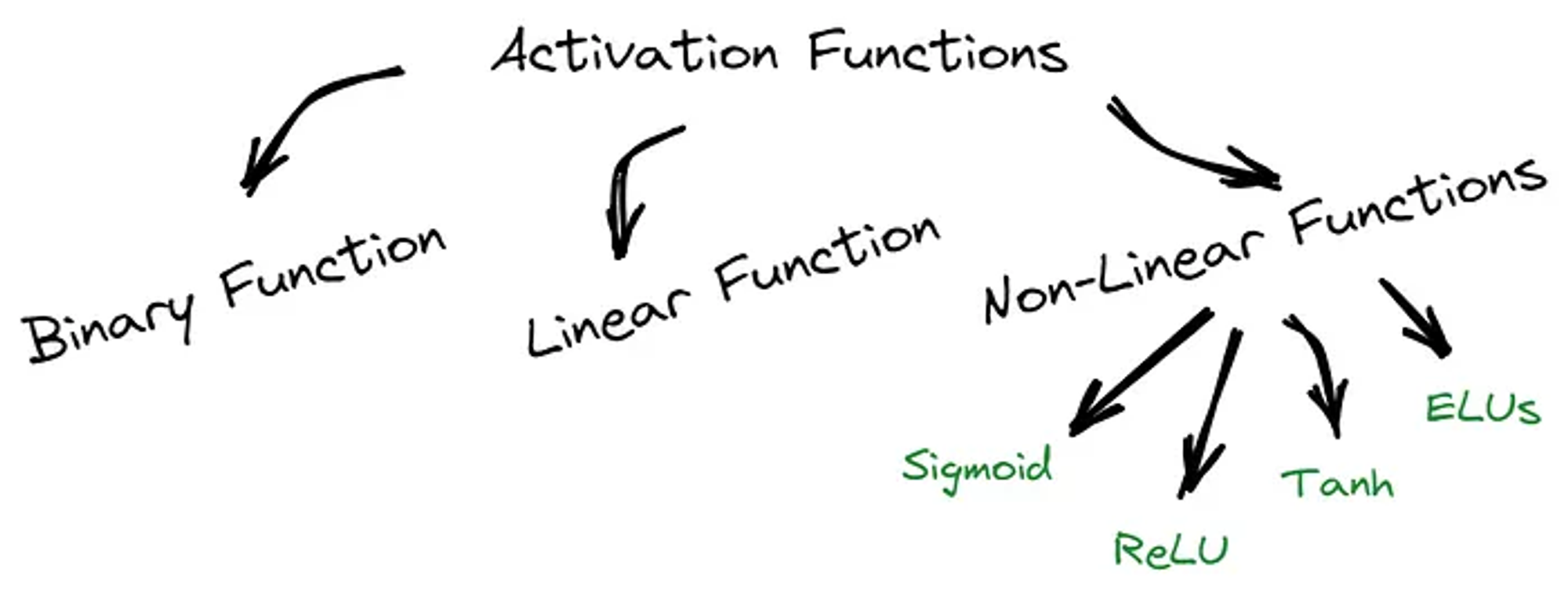
And there are 6 mostly used Activation Function from sigmoid to Relu. Let’s dig in!
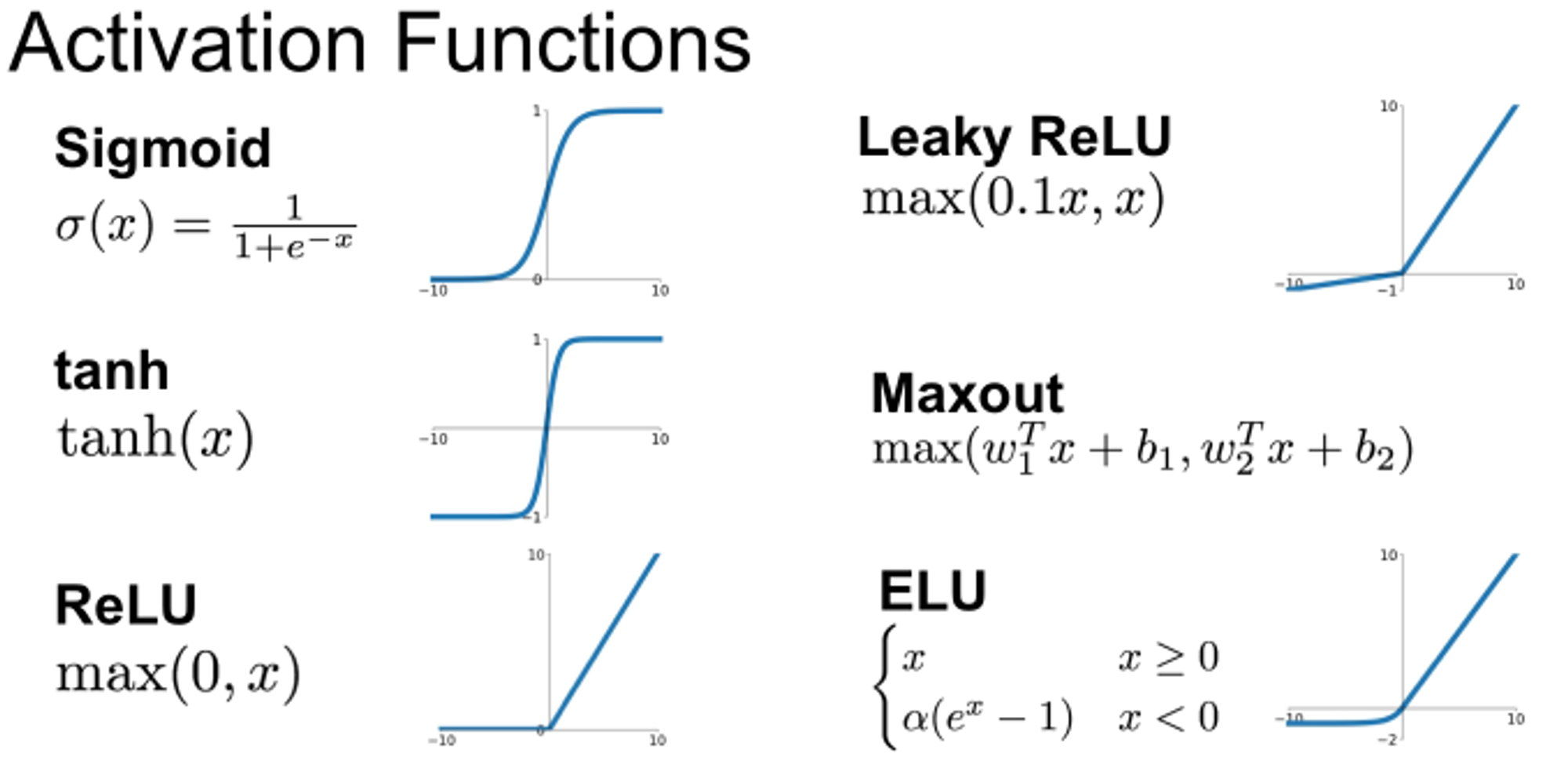
1. Sigmoid Function
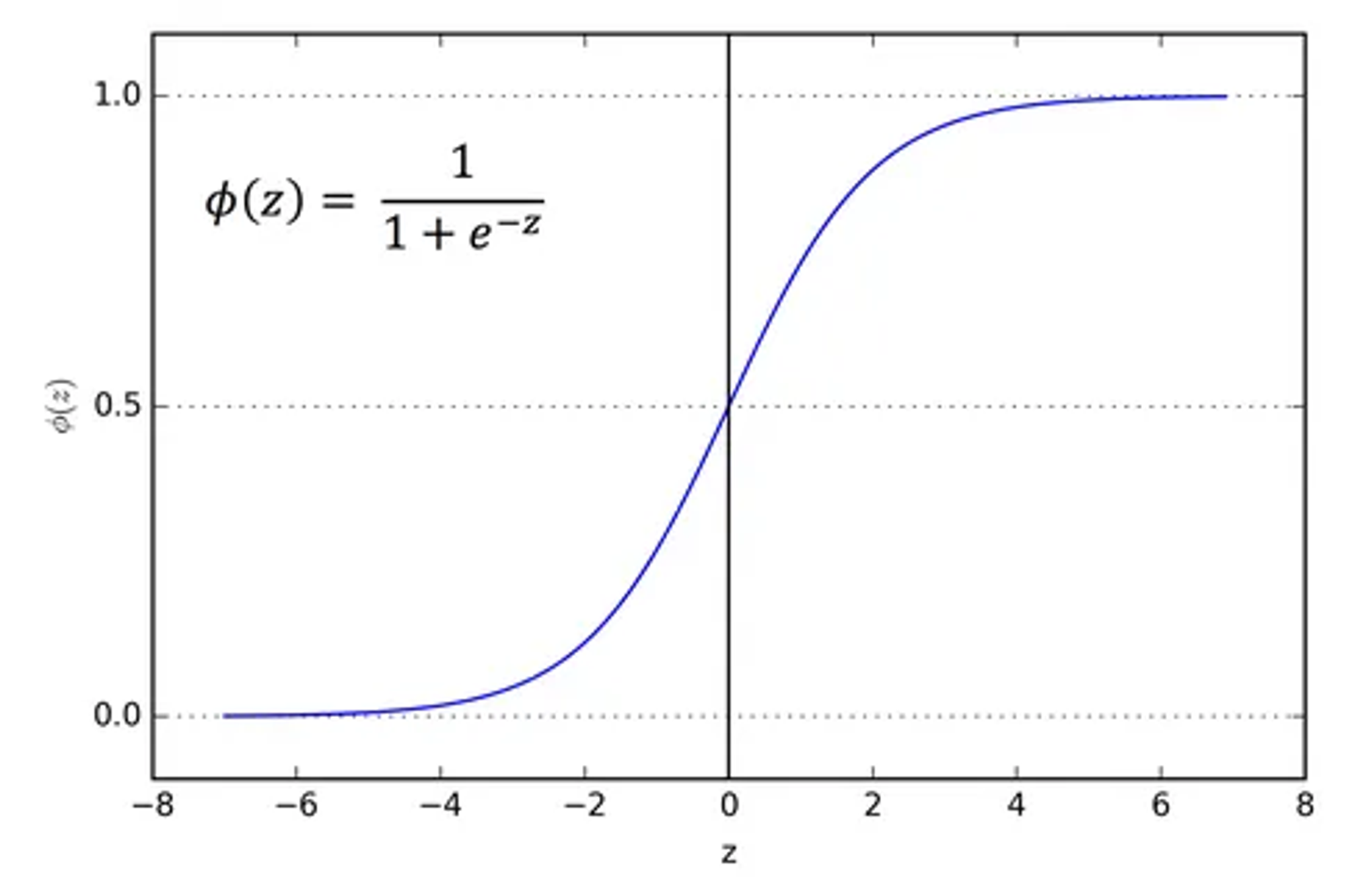
It is especially used for models where we have to predict the probability as an output. (Because probability of anything exists only between the range of 0 and 1!)
(The shape itself is same with the Logistic Function but it ranges between 0 and 1)
Softmax Function is a more generalized logistic activation function which is used for multiclass classification while sigmoid is used for binary classification tasks.
🔀 Finite range (0,1) -> Stable Training
👍 Historically popular since they have nice interpretation as the firing rate of a neuron.
👎 But they have several problems.
- Saturated neurons kill the gradients
- Sigmoid outputs are not zero-centered.
- exp() is a bit compute-wise expensive.
2. Tanh / Hyperbolic Tangent Activation Function
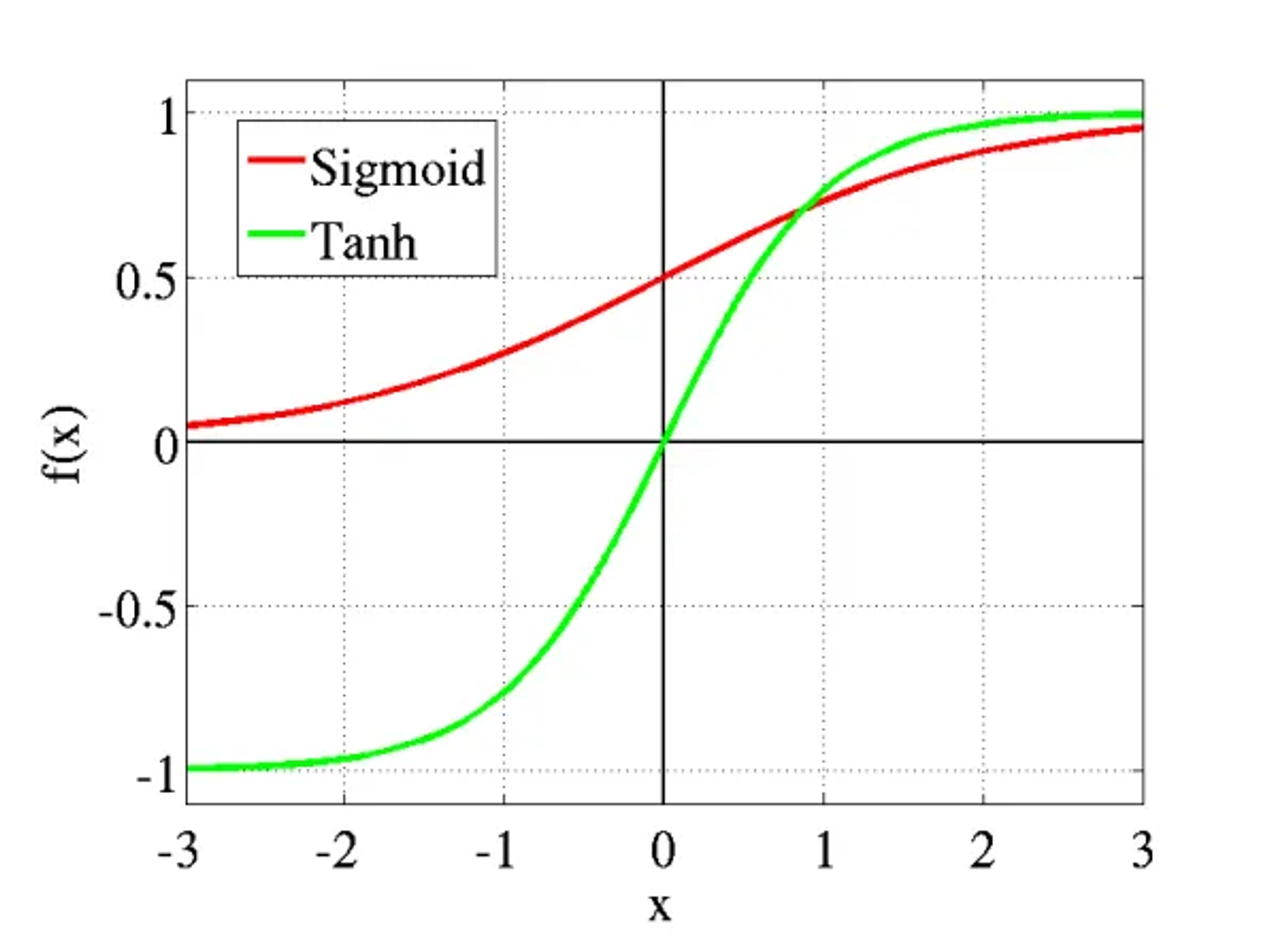
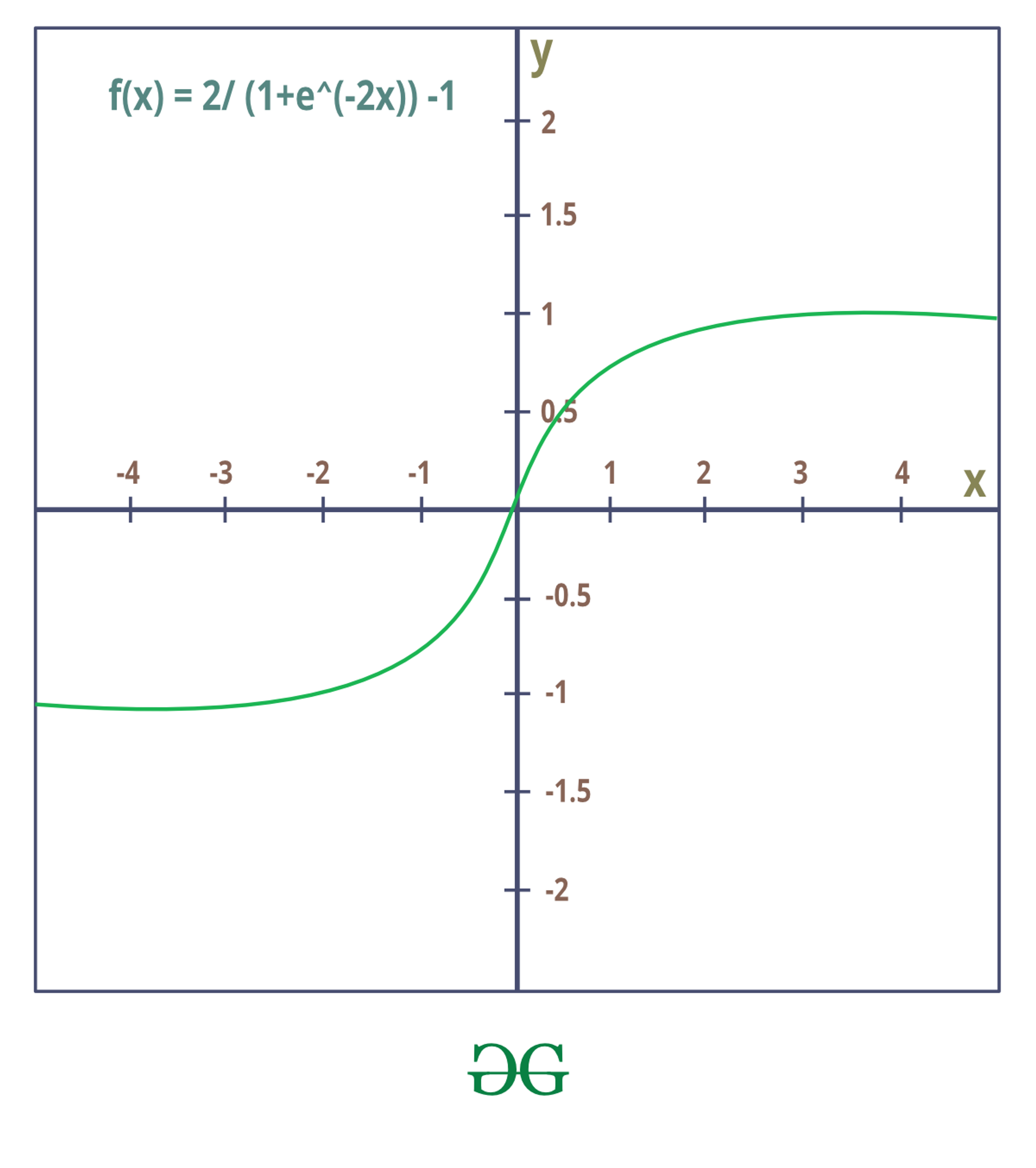
Tanh is also like logistic sigmoid but the range of it is different.
This is also mainly used to classify between two classes.
Usually used in the hidden layers of the neural network.
🔀 Finite range (-1,1)
👍the negative inputs will be mapped strongly negative and the zero will be mapped near zero ( zero-centered!)
It has stronger and steeper gradients.
👎 But it still kills gradients when saturated.
3. ReLU (Rectified Linear Unit) Activation Function
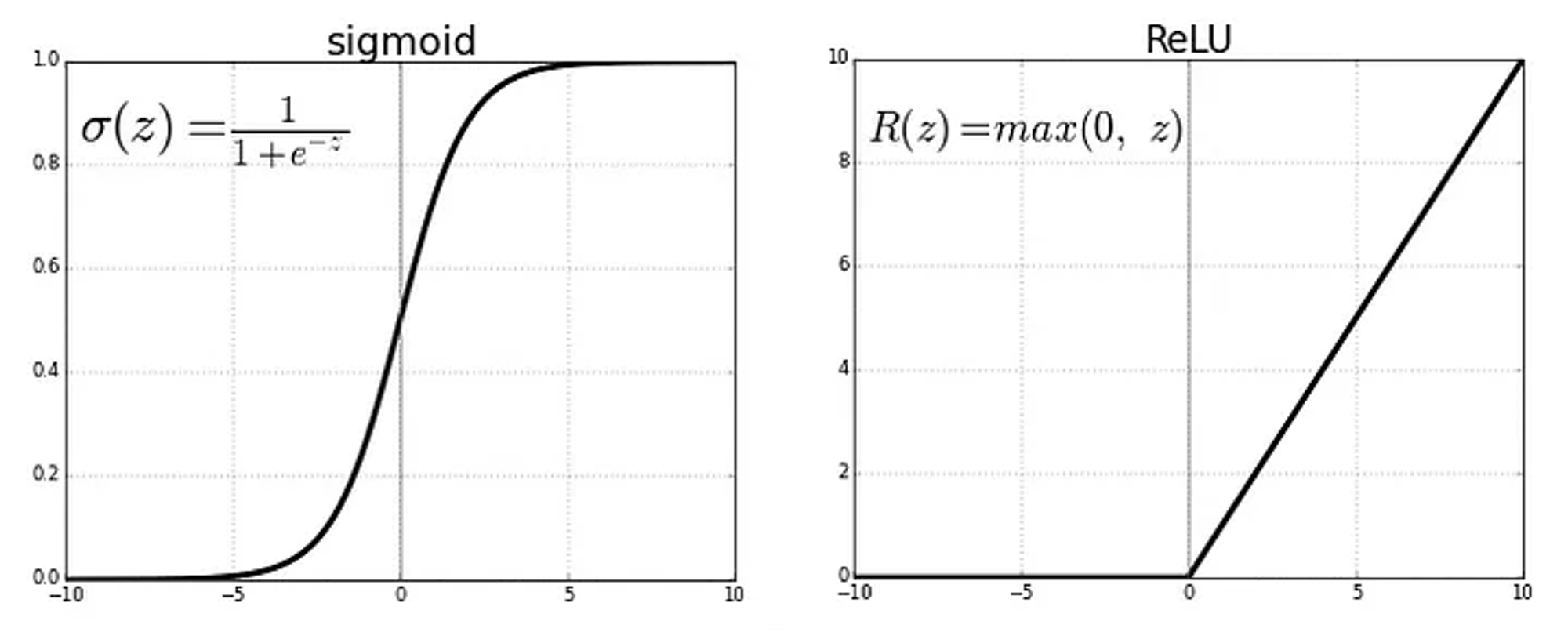
It is the most used activation function in the world right now!
(Utilized in AlexNet from ImageNet 2012)
Also used in the hidden layers of Neural Network.
🔀 range(0, Infinity) -> It can blow up the activation and destabilize training but it was presented to greatly accelerate the convergence.
If you don’t know what to use for your hidden layer, highly recommend to use ‘ReLU’ first.
👍 Does not saturate in a region which is bigger than 0. (+) = (avodies and rectifies vanishing gradient problem)
Computationally efficient, Converges much faster than sigmoid/tanh (e.g. 6 times more)
👎 Gradient vanishes when x<0 -> will never activate = never update
Not zero-centered
Dead ReLU can be happened.
(1) when the initialization goes wrong -> people like to initializae the neurons with slightly positive biases(e.g. 0.01)
(2) when the learning rate is too big -> The learning phase goes out of the data manifold.
4. Leaky ReLU
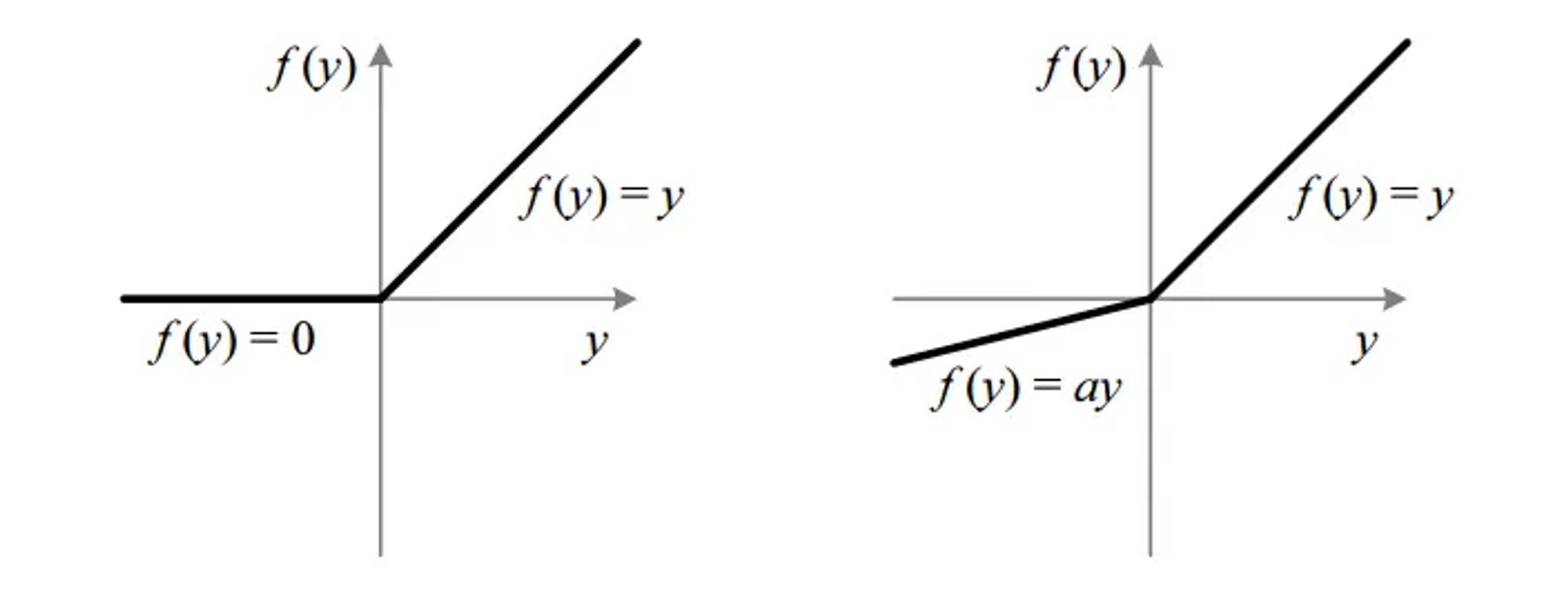
(L) ReLU (R) Leaky ReLU
It is similar to ReLU but not 0 anymore in the negative region.
🔀 range(-infinity, iinfinity)
max(0.01x, x)
👍It does not saturate
But still computationally efficient
Converges much faster than sigmoid/tanh (e.g. 6x)
No DEAD ReLU anymore
👎
5. LU Family
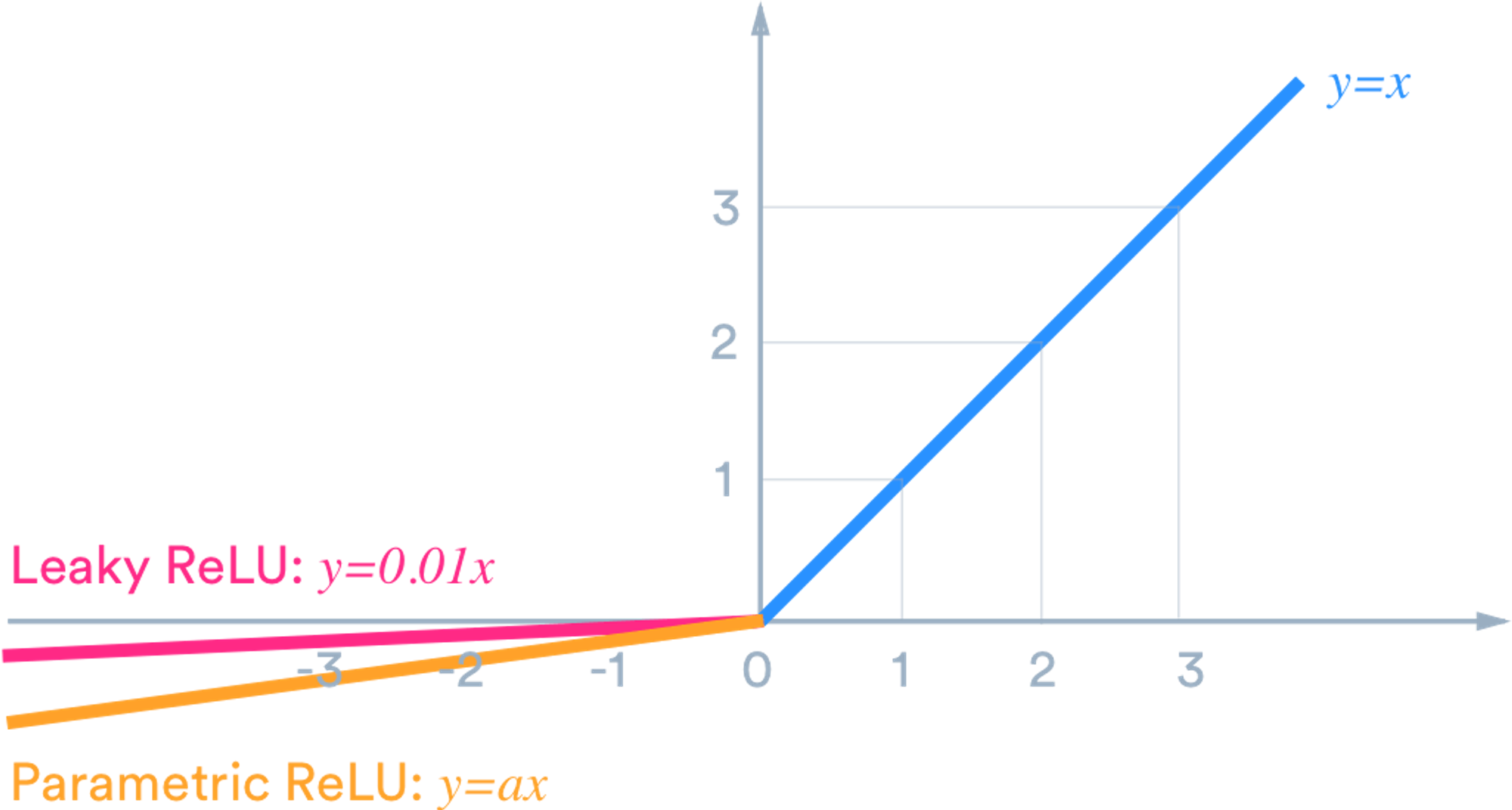
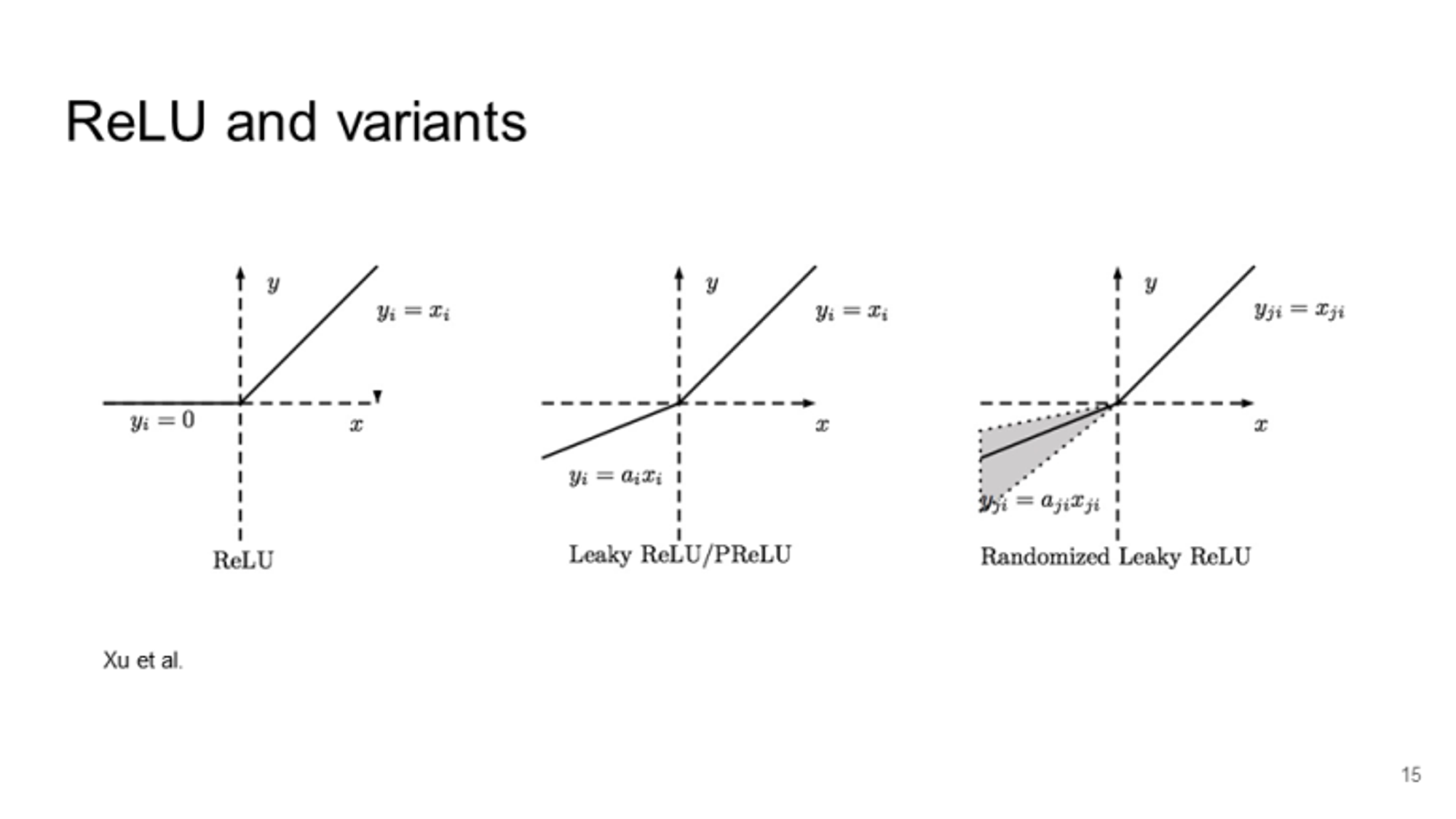
PReLU
Similar to ReLU but backprop into /alpha(parameter)
when alpha is 0.01, then it is as same as Leaky ReLU.
🔀 range(ax, x)
👍it has been shown to work well in some types of tasks, specifically in image recognition tasks.
same advantages as ReLU
👎
ELU (Exponential Linear Units)
ELU becomes smooth slowly until its output equals −α whereas ReLU sharply smoothes.
Unlike ReLU, ELU can produce negative outputs.
🔀 range(a(hyperparam), infinite)
👍it has been shown to work well in some types of tasks, specifically in image recognition tasks.
having all the good things about ReLU
almost zero-centered.
same advantages as ReLU
👎 for x > 0, it can blow up the activation with the output range of [0, inf].
6. MaxOut
Conclusion tips
- ReLU activation function should only be used in the hidden layers.
- Try Leaky ReLU, Maxout, ELU
- You can try Tanh, but don’t expect too much.
- Sigmoid/Logistic and Tanh functions should not be used in hidden layers as they can cause problems during training.
- Regression — Linear Activation Function
- Binary Classification — Sigmoid/Logistic Activation Function
- Multiclass Classification — Softmax
- Multilabel Classification — Sigmoid
ㄹㅇ 쉬운 딥러닝 4강 : 활성함수가 없으면 뉴럴네트워크가 아님 (Activation Function)
https://deepinsight.tistory.com/95
https://deepinsight.tistory.com/113
https://towardsdatascience.com/activation-functions-neural-networks-1cbd9f8d91d6
https://towardsdatascience.com/sigmoid-and-softmax-functions-in-5-minutes-f516c80ea1f9
https://www.geeksforgeeks.org/activation-functions-neural-networks/
https://medium.com/@Coursesteach/deep-learning-part-23-activation-functions-4b7941463846 -> This sums up all the pro tips about how to use activation function
https://datascience.stackexchange.com/questions/102483/relu-vs-leaky-relu-vs-elu-with-pros-and-cons -> show the difference between LU family