
BERT
Pre-training of Deep Bidirectional Transformers for Language Understanding
Background
From Attention is all you need (Transformer)
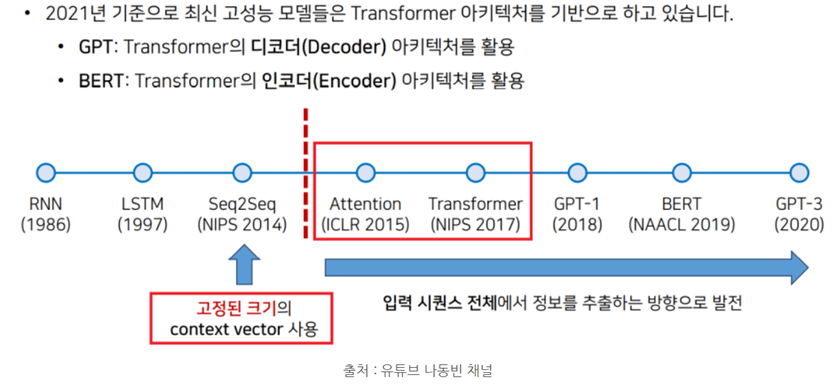
transformer가 나온 후에
분리해서 생각해보니까
인코더를 이용해서 의미를 추출하고 디코더를 이용해서 문장을 생성하면 더 좋은 퀄리티로 더 많은 태스크를 할 수 있을 수도..?!
이 때문에 문장생성에 Decoder만 몇 층 쌓은 GPT + 문장의미추출에 Encoder만 12 층 쌓은 BERT를 만듦
BERT (from Google)
- Transformer’s Encoder
- MLM학습으로 인하여, 동시에 연산이 가능 → 속도가 빨라짐
GPT (from OpenAI)
- Transformer’s Decoder
- LM(언어모델) 학습으로 인하여 결국 lstm처럼 앞의 토큰 예측이 끝나야 다음 토큰 예측 가능→ BERT보다 속도는 훨씬 느림
- Decoder block이 순방향 attention만을 쓰기 때문에 문장 생성에 직접적으로 이용될 수 있는 강점을 가짐.
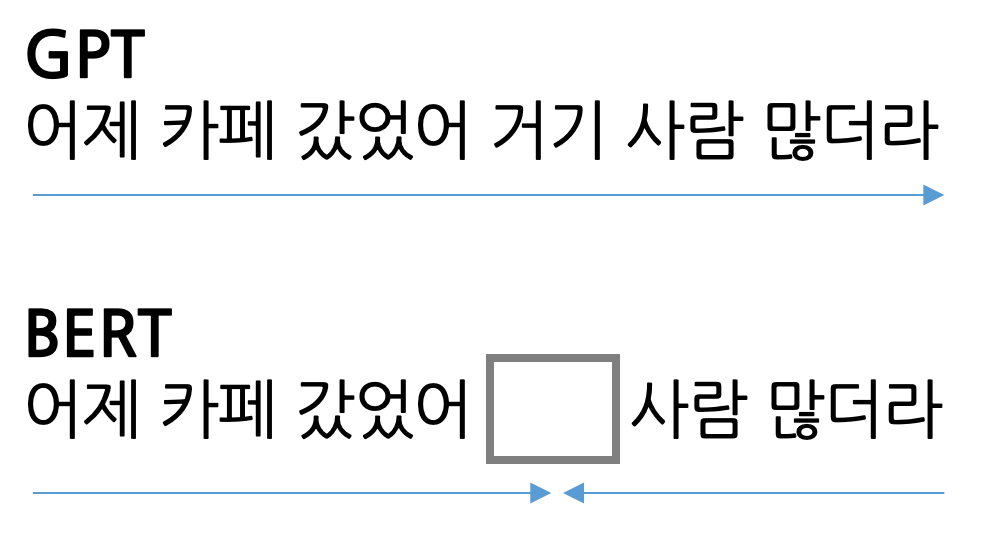
> 가장 큰 차이점은 Attention의 참조방향이 순방향이냐 양방향이냐는 것.
BERT
(Bidirectional Encoder Representations from Transformers)
bidirectional encoder : 문맥을 양방향으로 이해해서 입력값을 숫자의 형태로 바꾸어주는 모델
트랜스포머를 이용하여 구현되었으며, 위키피디아(25억 단어)와 BooksCorpus(8억 단어)와 같은 레이블이 없는 텍스트 데이터로 사전 훈련된 언어 모델
- Transformer의 인코더를 적층해서 맨 뒤에 Layer 하나만 붙임 (Fine-Tuning)
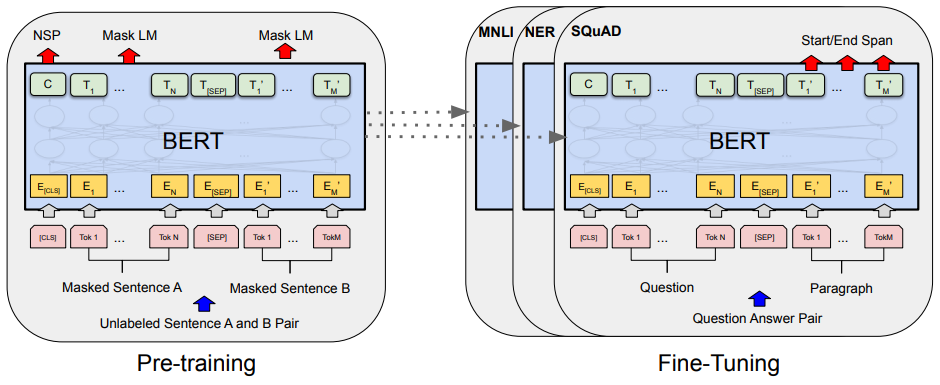
- Unlabeled 방대한 데이터로 사전훈련된 모델을 가지고 특정 태스크의 라벨링된 데이터로 전이학습하는 모델
- 레이블이 있는 다른 task에서 추가 훈련과 함께 hyperparameter를 재조정하는 fine-tuning 을 거치면 성능이 좋음.
- 잘 만들어진 BERT 언어모델 위에 1개의 classification layer만 부착하여 다양한 NLP task를 수행
- 영어권에서 11개의 NLP task에 대해 state-of-the-art (SOTA) - 전부 최신성능 달성 !!
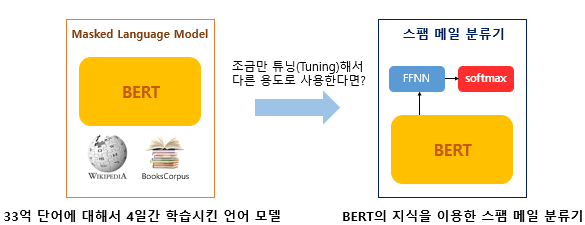
TASK == 스팸메일분류 라고하면, 이미 위키피디아 등으로 사전학습된 BERT위에 분류를 위한 신경망을 한 층 추가함.
이 경우 BERT가 Language Model Pre-train 과정에서 얻은 지식을 활용하여 » 스팸메일분류에서 보다 좋은 성능을 낼 수 있음.
분류문제 > Classification Layer를 하나 추가
기계독해> 정답의 위치를 출력하는 Layer 추가
개체명인식은 각 토큰마다 벡터가 나오기 때문에 각 토큰마다 tagging 을 하도록 Layer를 추가
이렇게 트랜스포머 인코더 12개 위에 출력되는 출력층에 Layer를 하나만 추가를 하면 각종 task들을 좋은 성능으로 수행해낼 수 있음
How big BERT is?

base ver. 12개의 Transformer Encoder
Large ver. 24개의 Transformer Encoder
이 外에도 Large ver.은 Base ver.보다 d_model의 크기나 self attention head의 수가 더 큽니다.
-트랜스포머 인코더 층의 수를 L, d_model의 크기를 D, 셀프 어텐션 헤드의 수를 A
- BERT-Base : L=12, D=768, A=12 : 110M개의 파라미터
- BERT-Large : L=24, D=1024, A=16 : 340M개의 파라미터
*초기 트랜스포머 모델이 L=6, D=512, A=8이었다는 것과 비교하면 Base 또한 초기 트랜스포머보다는 큰 네트워크임을 알 수 있습니다.
BERT 학습방법
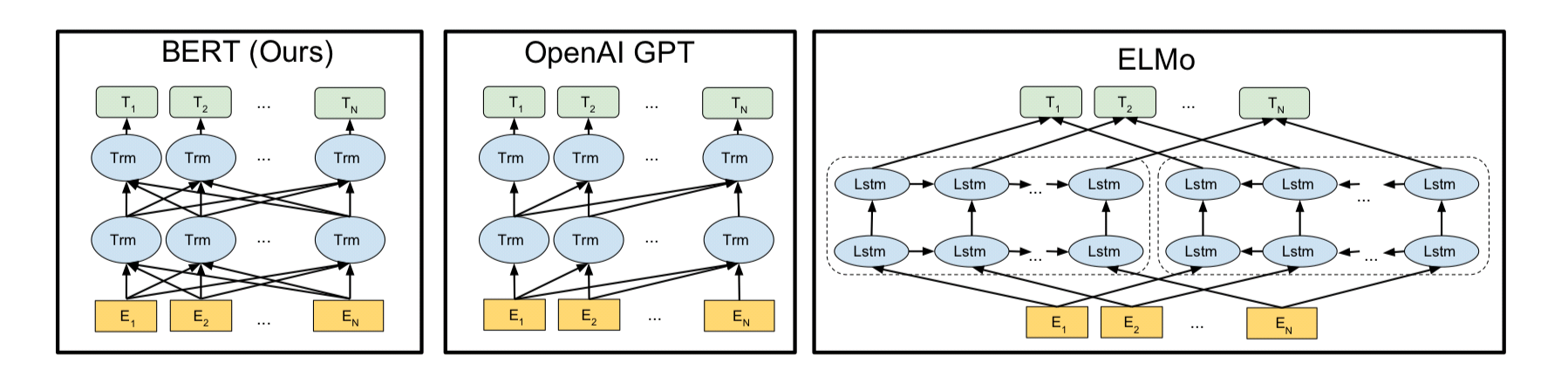
(논문에 첨부된 그림)
- 기존방법 : 이전단어들로부터 다음 단어를 예측하는 단방향 기법
- ELMo는 정방향 LSTM과 역방향 LSTM을 concat하여 이를 극복하고자 했지만 성과는 미미했음
- GPT는 트랜스포머의 디코더를 이전단어들로부터 다음 단어를 에측하는 방식으로 단방향 언어모델을 만듦.
- 가장 좌측 BERT는 화살표가 양방향으로 뻗어나가는 모습을 보임! 이는 MLM(Masked Language Model)을 통해 양방향성을 얻었기 때문
BERT ARCHITECTURE
Embedding Layers + Transformer’s Encoder
Embedding
Word embedding + Character Embedding 을 섞은 방식을 활용
- 일단 토큰 단위로 분리하되, 자주 나오는 글자들은 병합하여 하나의 토큰으로 만든다. (서브워드토크나이저 : Wordpiece)
- MLM/NSP 을 수행하여 사전학습을 하기 위해서 input을 3개의 embedding의 합으로 표현
Token Embedding (Wordpiece): 실질적인 입력이 되는 임베딩Positional Embedding: 위치 정보 학습Segment Embedding: 두 개의 문장을 구분
1. Wordpiece Embedding (Subword Tokenizer)
단어 집합의 크기가 30,522개인 단어 벡터를 위한 임베딩 층
**신조어, 오탈자 등도 딥러닝학습모델이 봤을만한 단어들로 인풋되기때문에 흔치않은 단어들에 대한 예측이 향상됨
단어보다 더 작은 단위로 쪼개는 서브워드 토크나이저 사용
자주 등장하는 단어는 그대로 단어 집합에 추가하지만, 자주 등장하지 않는 단어의 경우에는 더 작은 단위인 서브워드로 분리되어 서브워드들이 단어 집합에 추가된다.
Byte Pair Encoding(BPE)와 유사
- *byte-pair encoding (GPT)
자주 함께 사용되는 캐릭터를 하나의 묶음으로 사용, word, char embedding의 장점을 가지고있음
word-embedding 장점 : 단어간의 유사도를 가지고있음, 학습시에 보지못했던 단어는 단순히 유사도가 전혀없는 zero-vector로 처리되기떄문에 신조어, 오탈자등에 약함
word embedding ( trained on unlabeled corpora)
character-embedding : 단어는 일정한 양의 캐릭터로 구성된 집합이기 때문에 zero-vector가 나올확률이 거의없지만 단어간의 유사도는 word embedding보다 낮음
ex) Hackable deep learning
- word embedding에서는 zero-vector가 될 확률이 큼
- byte-pair embedding 에서는 hack, able 로 분리해서 의미 간직, word,char embedding보다 입력값의 의미를 더 잘 전달했기 때문에 더 나은 모델 성능 기대가능
이미 훈련 데이터로부터 만들어진 단어 집합이 필요하고
토큰이 이 단어집합에 존재하면 > 해당 토큰을 분리하지 않고
존재하지 않을 시에 > 해당 토큰을 서브워드로 분리하고 첫번째 서브워드를 제외한 나머지 서브워드들은 앞에 ‘##’를 붙인다.
그래서 googling이라는 신조어가 들어왔을 때 다른 토크나이저는 OOV(Out-Of-Vocabulary) 문제가 발생하지만
서브워드 토크나이저는 당황하지않고 이를 google 과 ing로 쪼갭니다. 이는 두가지 뜻을 어느정도는 학습할 수 있습니다.
2. Positional Embedding
-각 토큰들의 상대적인 위치 _ RNN, LSTM 과는 다르게 순차적으로 학습되는 모델이 아니고 한번에 한 문장의 모든 토큰을 병렬적으로 처리하기 때문에
- Unlike LSTMs , Transformers and BERT don’t have locational awareness
*상대적인 위치 사용하는 이유: 학습 데이터에서 나온 최장길이의 문장보다 더 큰 길이의 문장을 받을 수 없기때문에 상대적위치 선호.

Transformer : Positional Encoding이라는 방법 통해서 단어의 위치 표현
**Positional Encoding (사인 함수와 코사인 함수를 사용하여 위치에 따라 다른 값을 가지는 행렬을 만들어 이를 단어 벡터들과 더하는 방법)
BERT에서는 이와 유사하지만 위치정보를 Sine, Cosine 함수로 만드는 것이 아닌 학습을 통해서 얻는 Position Embedding 사용
위치 정보를 위한 임베딩 층(Embedding layer)을 하나 더 사용
문장의 길이가 4라면 4개의 포지션 임베딩 벡터를 학습
BERT의 입력마다 다음과 같이 포지션 임베딩 벡터를 더해주는 것입니다.
- 첫번째 단어의 임베딩 벡터 + 0번 포지션 임베딩 벡터
- 두번째 단어의 임베딩 벡터 + 1번 포지션 임베딩 벡터
- 세번째 단어의 임베딩 벡터 + 2번 포지션 임베딩 벡터
- 네번째 단어의 임베딩 벡터 + 3번 포지션 임베딩 벡터
실제 BERT에서는 문장의 최대 길이를 512로 하고 있으므로, 총 512개의 포지션 임베딩 벡터가 학습됩니다.
3. Segment Embeddings
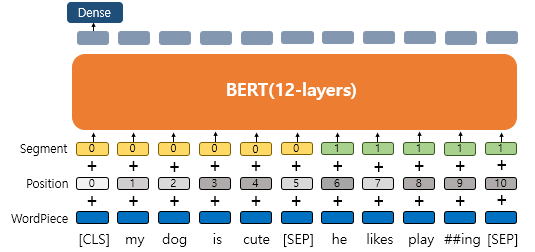
QA등과 같은 두개 문장 입력이 필요한 태스크도 풀기 때문에 문장 구분을 위해 사용
두 문장이 입력될경우 두개의 문장의 서로 다른 숫자들을 부여.
첫번째문장에는 sentence -, 두번째문장에는 sentence 1 임베딩을 더해주는 방식이며 임베딩 벡터는 이렇게 두개만 사용됨.
-딥러닝 모델에게 서로 다른 두개의 문장이 있다는것을 쉽게 알려주기위해 사용됨
결론적으로 BERT는 총 3개의 임베딩 층이 사용됩니다.
WordPiece Embedding: 실질적인 입력이 되는 워드 임베딩. 임베딩 벡터의 종류는 단어 집합의 크기로 30,522개.Position Embedding: 위치 정보를 학습하기 위한 임베딩. 임베딩 벡터의 종류는 문장의 최대 길이인 512개.Segment Embedding: 두 개의 문장을 구분하기 위한 임베딩. 임베딩 벡터의 종류는 문장의 최대 개수인 2개.
BERT Layer (Transformer’s Encoder)
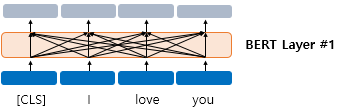
BERT의 첫번째 층에 입력된 각 단어가 모든 단어를 참고한 후에 출력되는 과정 (문맥파악)
이 첫째 층의 출력 임베딩은 둘째 층의 입력 임베딩으로 이용
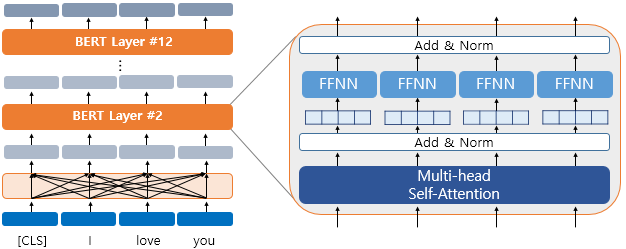
12번 반복.
이 문맥 반영 출력 임베딩은 아시다시피 transformer의 encoder 구조 와 같음
Multi-head self attention & Position wise Feed Forward Neural Network
<BERT 모델의 (PRE-TRAIN)을 위해 사용한 2가지>
- BookCorpus(8억 단어) + Wikipedia (25억 단어)
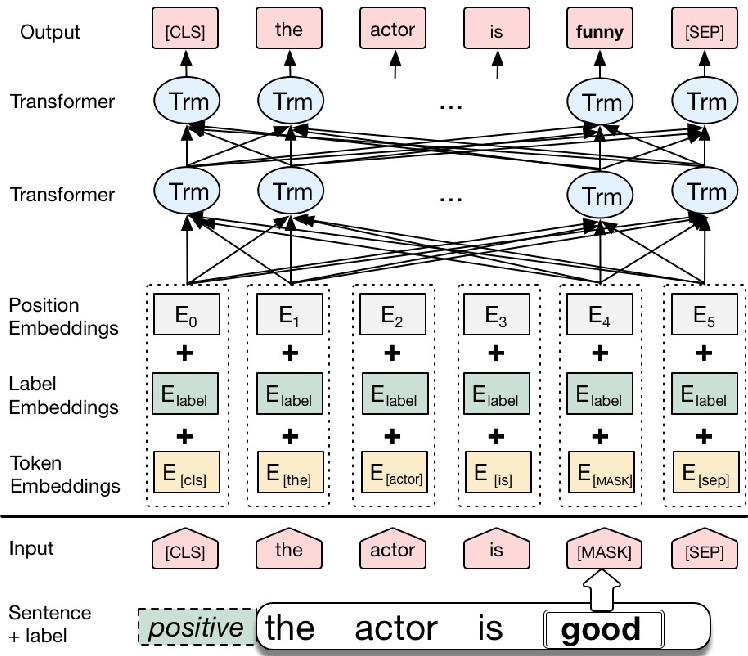
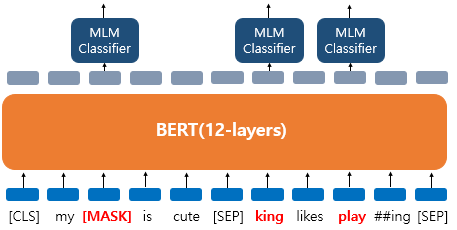
1. MLM (Masked Language Model)
- Unlike unidirectional context which builds representation incrementally, Bidirectional context can actually “see themselves” so -> 문장 내 일부 단어를 가리고, 문맥을 통해 어떤 단어가 들어갈지 맞추는 학습방법 사용
입력 텍스트의 15%의 단어를 랜덤으로 masking > 그리고 인공 신경망에게 이 masked words를 맞추게함
- If there’s too little masking, then it’s going to be too expensive to train
- If there’s too much masking, then it’s going to be not enough context to train
- Downside : we can’t get as many predictions per sentence, we’re only getting predicting 15% of words instead of 100% words
- Upside : We get a much more rich model because we’re seeing in both directions
더 정확히는 전부 [MASK]로 변경되지는 않고, 랜덤으로 선택된 15%의 단어들은 또 다음과 같은 규칙을 따른다.
80%의 단어들은 [MASK]로 변경
10%의 단어들은 랜덤단어로 변경
10%의 단어들은 그대로 동일하게 둠. ( 두어도 BERT는 이게 본문장의 단어인지 랜덤단어로 변경된건지 맞춰야함)
- ‘dog’ 토큰은 [MASK]로 변경
- ‘he’는 랜덤 단어 ‘king’으로 변경
- ‘play’는 변경되진 않았지만 예측에 사용
2. NSP (Next Sentence Prediction)
- 주어진 문장 다음에 두가지 문장을 제시하여, 둘중 어느 문장이 문맥상 이어질지 맞추는 방법
- 토큰간의 상관관계 뿐만 아니라 문장간의 상관관계를 고려하기위해 필요한 과정
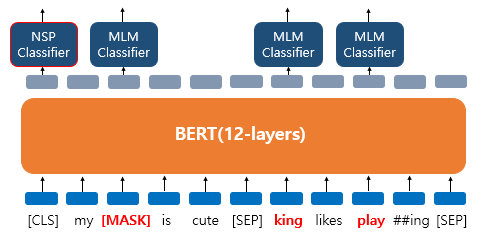
BERT의 입력에는 [SEP]라는 특별 토큰을 사용하여 문장을 분리.
첫번째 문장의 마침에, 그리고 두번째 문장의 마침에도 [SEP] 토큰 사용.
그리고 이 두 문장이 실제 이어지는 문장인지 아닌지는 [CLS] 토큰의 위치의 출력층에서 이진 분류 문제를 풂.
**[CLS] 토큰 : BERT가 분류 문제를 풀기 위해 추가된 특별 토큰.
위의 그림에서 나타난 것과 같이 MLM(Masked Language Model)과 NSP(Next Sentence Prediction)은 따로 학습하는 것이 아닌 loss를 합하여 학습이 동시에 이루어짐.
- BERT가 언어 모델 외에도 다음 문장 예측이라는 태스크를 학습하는 이유
BERT가 풀고자 하는 태스크 중에 QA(Question Answering)나 NLI(Natural Language Inference)와 같이 두 문장의 관계를 이해하는 것이 중요한 태스크들이 있기 때문
Pre-trained BERT 모델 완성!!
FINE-TUNING
- There are 2 ways in FINE-TUNING
FEATURE-BASED: 추가적인 특정 task를 할 수 있도록 새로운 사전학습 모델을 추가 (ELMo)
임베딩은 그대로 두고 그 위에 레이어만 학습 하는 방법
FINE-TUNING: 특정 task에 특화된 파라미터를 최대한 줄이고, 전체 신경망의 가중치를 조정한 지도학습 (ex. GPT), 임베딩까지 모두 업데이트하는 기법
사전학습된 BERT + 풀고자하는 TASK의 데이터를 추가로 학습시켜 테스트하는 단계인 FINE-TUNING
1) 하나의 텍스트에 대한 텍스트 분류 유형(Single Text Classification)
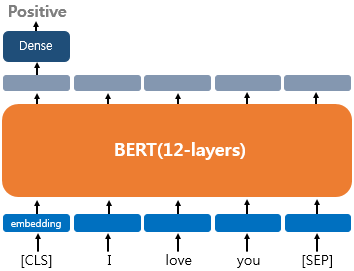
2) 하나의 텍스트에 대한 태깅 작업(Tagging)
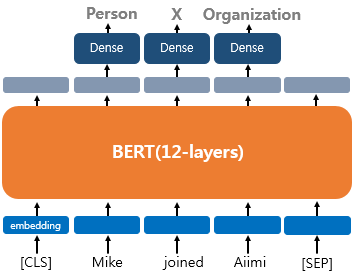
각 단어에 품사를 태깅하는 품사 태깅 작업과 개체를 태깅하는 개체명 인식 작업
3) 텍스트의 쌍에 대한 분류 또는 회귀 문제(Text Pair Classification or Regression)
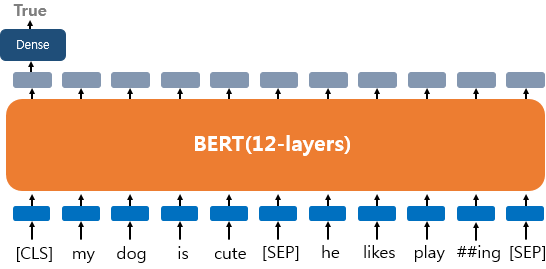
Natural Language Inference, 두문장이 어떤 관련이 있는지 (contradiction, entailment, neutral)
4) 질의 응답(Question Answering) !
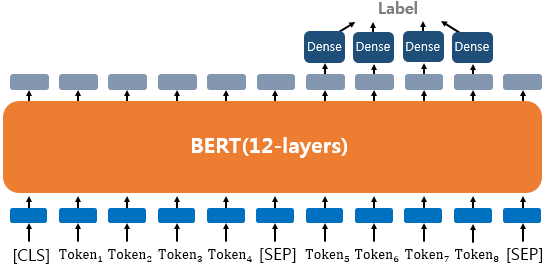
텍스트의 쌍을 입력으로 받는 또 다른 태스크로 QA(Question Answering)
SQuAD(Stanford Question Answering Dataset)
More…
- 훈련 데이터는 위키피디아(25억 단어)와 BooksCorpus(8억 단어) ≈ 33억 단어
- WordPiece 토크나이저로 토큰화를 수행 후 15% 비율에 대해서 마스크드 언어 모델 학습
- 두 문장 Sentence A와 B의 합한 길이. 즉, 최대 입력의 길이는 512로 제한
- 100만 step 훈련 ≈ (총 합 33억 단어 코퍼스에 대해 40 에포크 학습)
- 옵티마이저 : 아담(Adam)
학습률(learning rate) :
10−4
- 가중치 감소(Weight Decay) : L2 정규화로 0.01 적용
- 드롭 아웃 : 모든 레이어에 대해서 0.1 적용
- 활성화 함수 : relu 함수가 아닌 gelu 함수
- 배치 크기(Batch size) : 256
각주 및 추천자료
https://blog.pingpong.us/transformer-review/
https://zsunn.tistory.com/entry/AI-최신-기술-이해-및-실습-Transformers-Self-Attention-GPT-BERT-등
https://ratsgo.github.io/nlpbook/docs/language_model/bert_gpt/