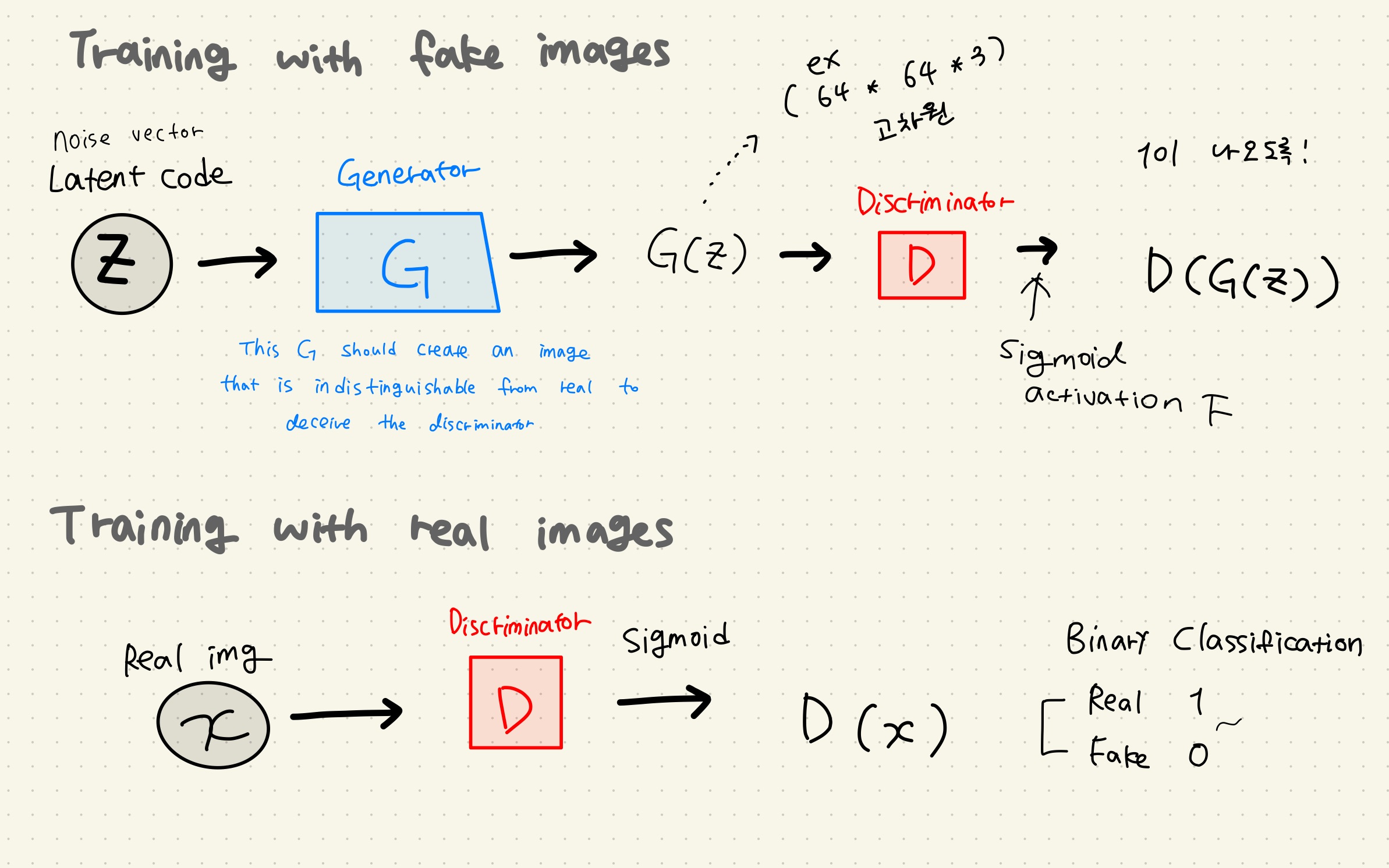
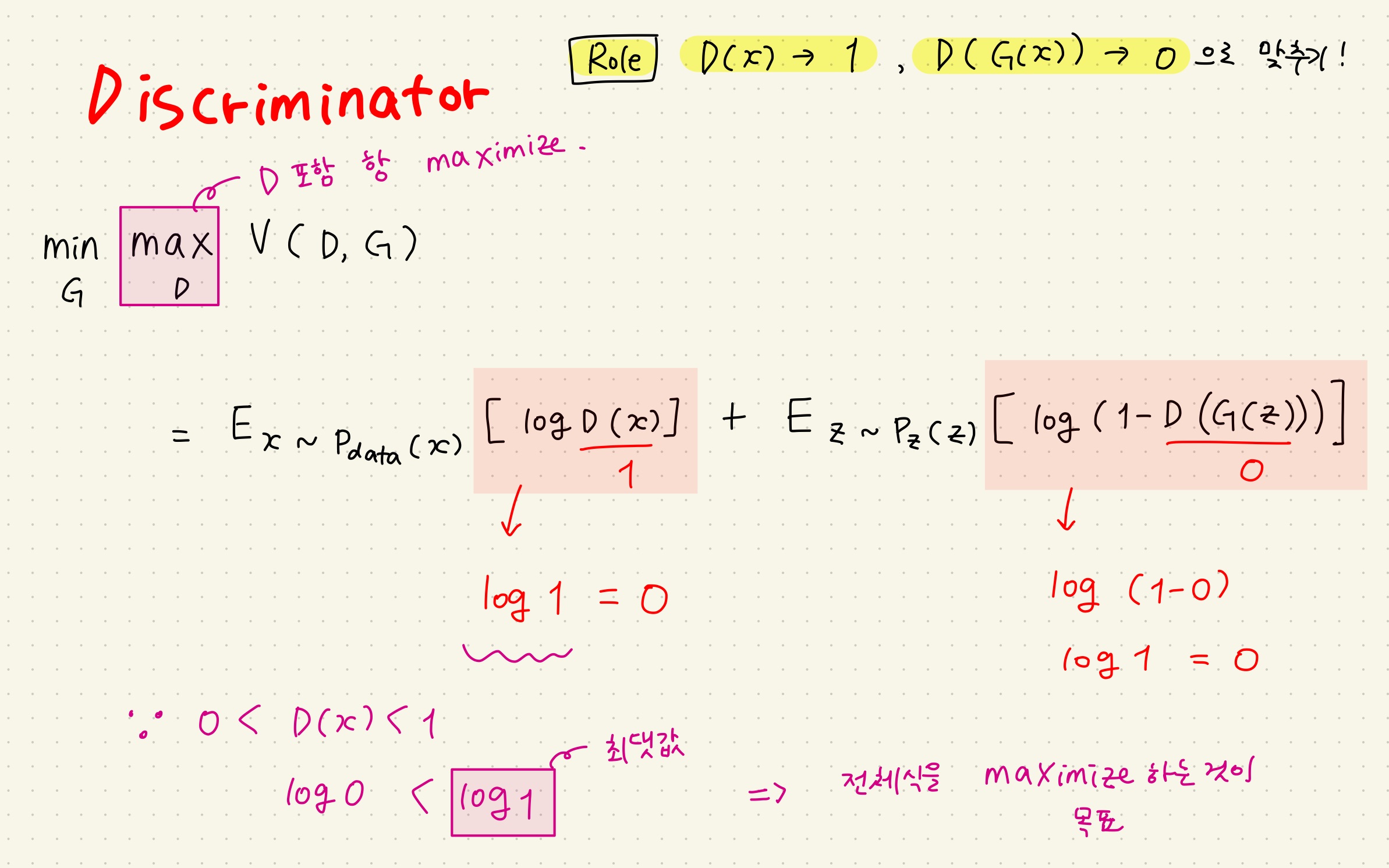
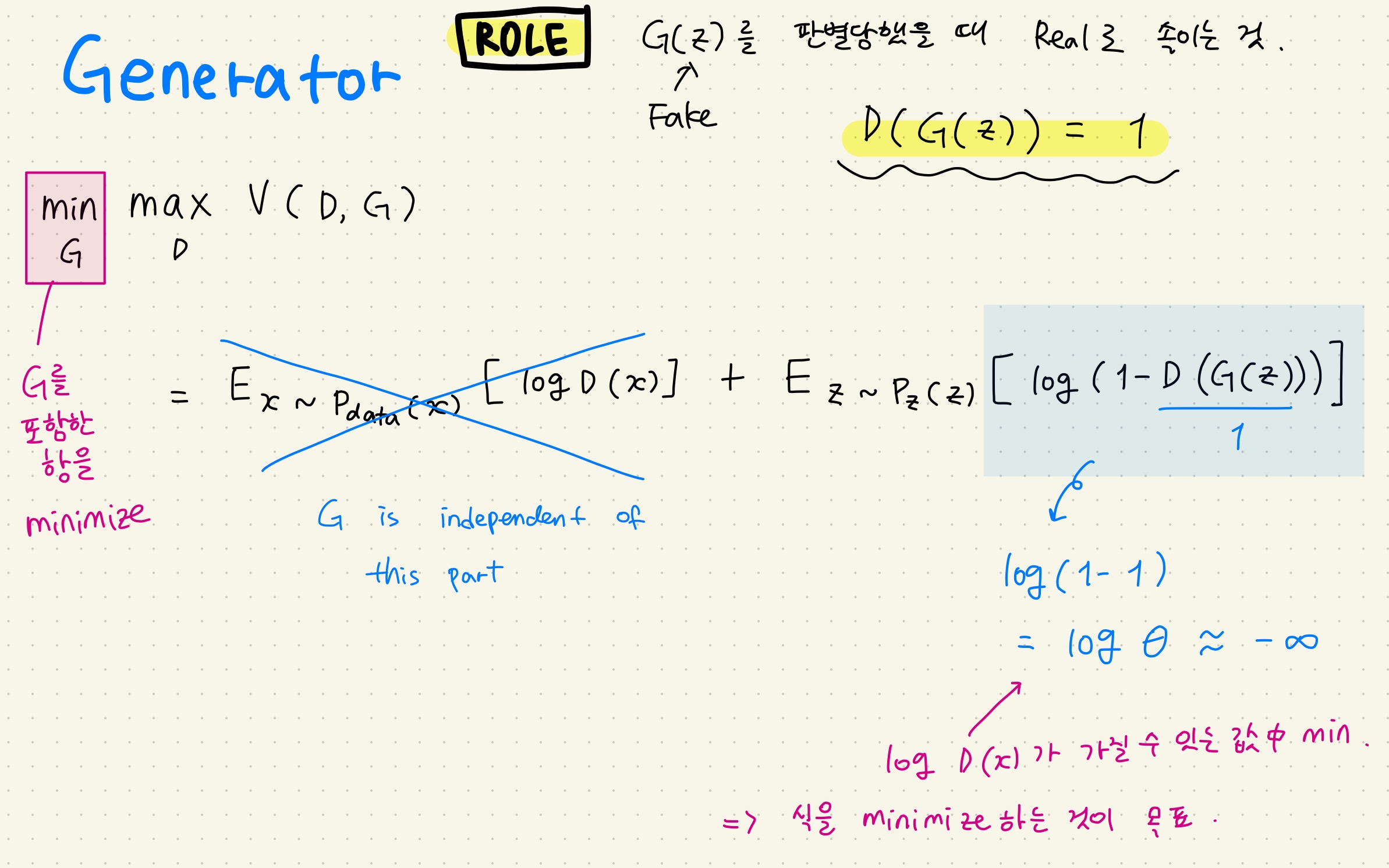
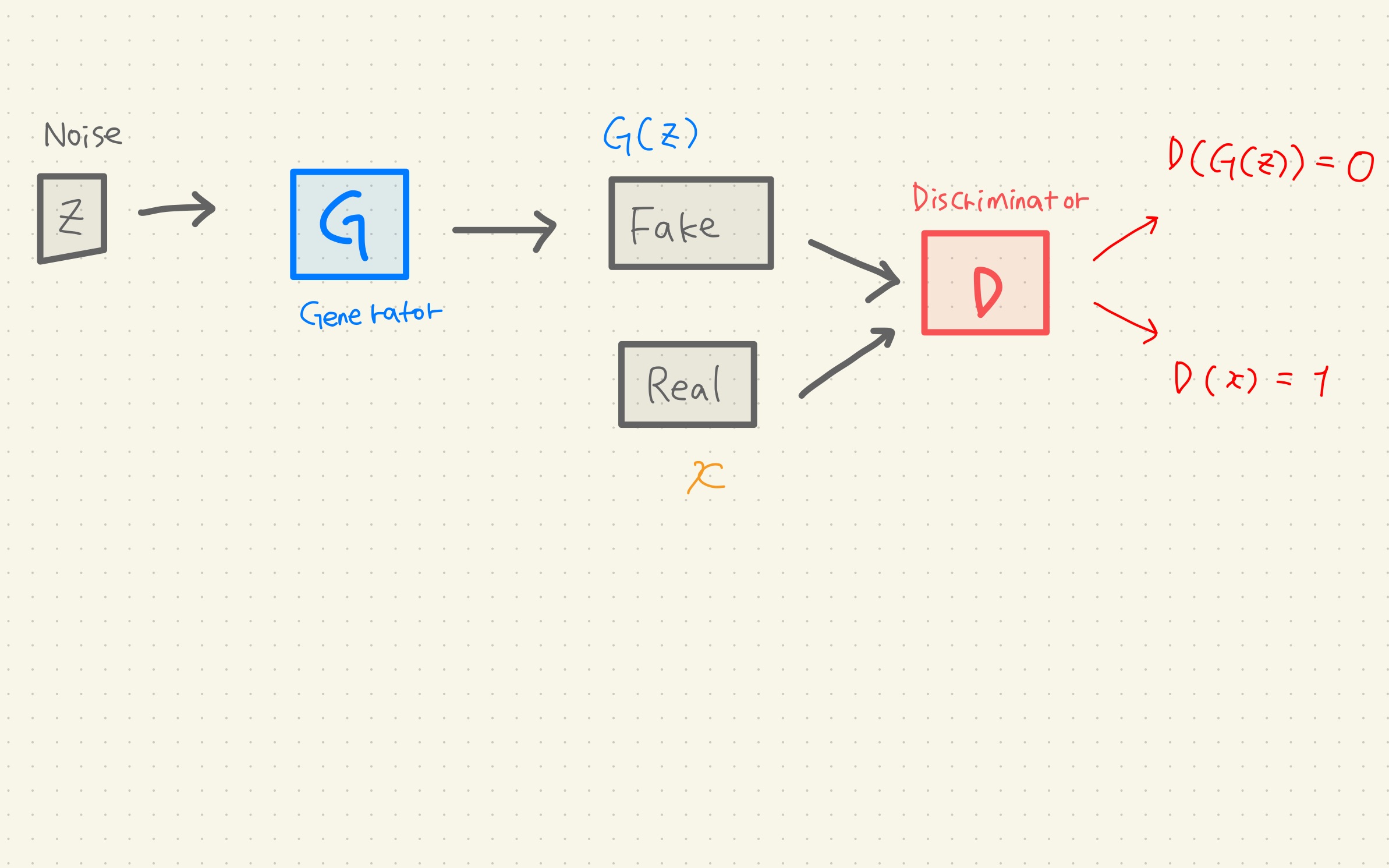
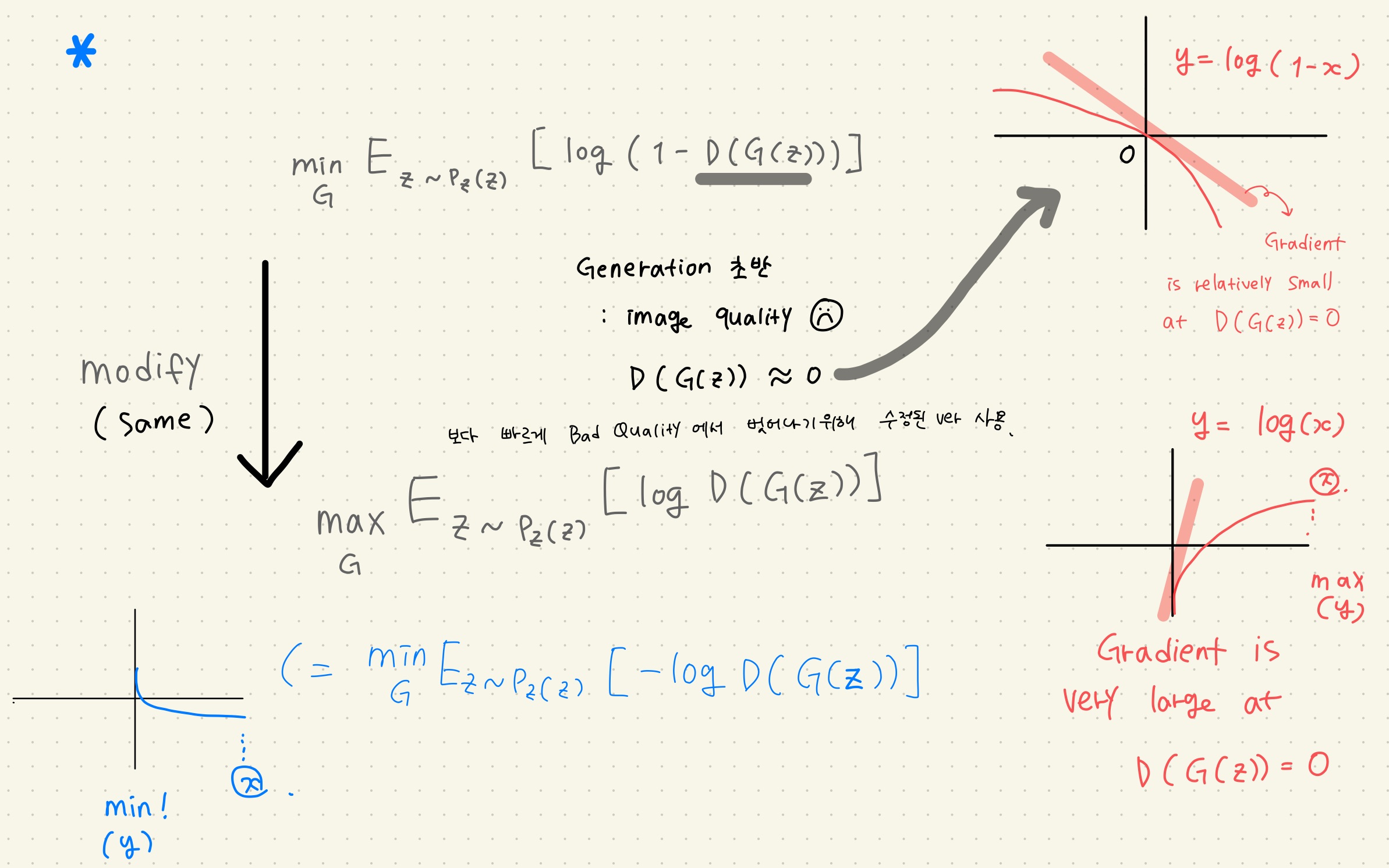
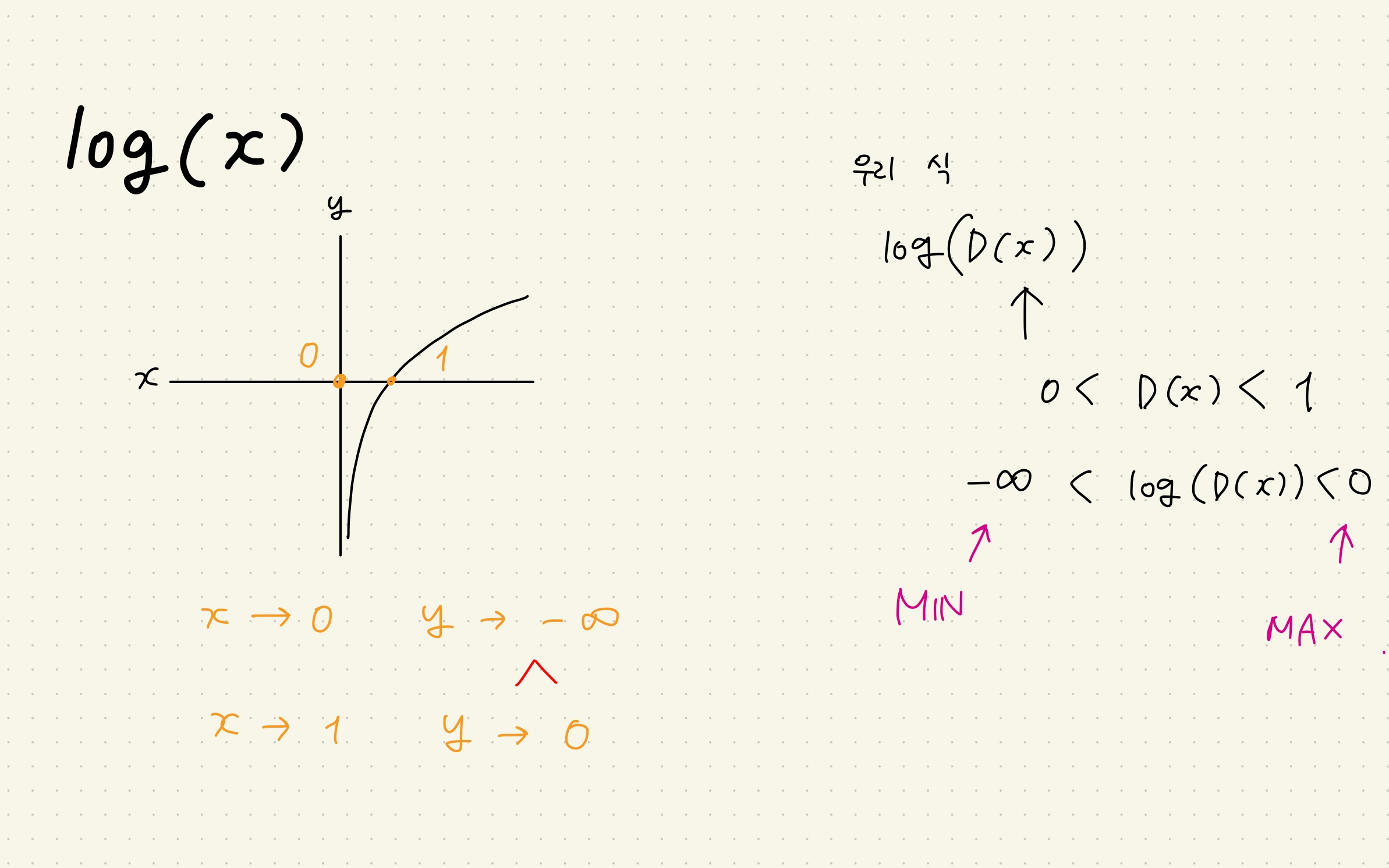BERT Pre-training of Deep Bidirectional Transformers for Language Understanding Background From Attention is all you need (Transformer) transformer가 나온 후에 분리해서 생각해보니까 인코더를 이용해서 의미를 추출하고...
GPT-1 Generative Pre-Training of a Language Model (Elmo와 idea 유사) Elmo -> GPT -> BERT Elmo 와의 차이점 Elmo : Bidirectional Language model 이용 (Forward, backward La...
RoBERTa Facebook AI Research (FAIR), 2019) (Robustly optimized BERT approach) The difference with BERT It shows the impact of many key hyperparameters and training data size with the thou...
RoBERTa
Recommender System (1) Intro