
GPT-1
Generative Pre-Training of a Language Model
(Elmo와 idea 유사)
Elmo -> GPT -> BERT
Elmo 와의 차이점
Elmo : Bidirectional Language model 이용 (Forward, backward Language Model 이용
GPT : Transformer 의 Decoder만 이용 (No Backward, only masked Forward 이용)
Motivation
: Unlabeled Text Corpora 가 세상에 많아서 이것을 이용해서 Generative Pre-training of a language model 을 이용해서 Embedding vector 를 생성
- way better than just using Labeled Text Corpora for a specific Task
Language Model : 현재 알고있는 단어를 기반으로 다음 단어를 예측하는데 쓰임
왜 gpt가 language model을 쓰는가 : Language model은 labeling 이 필요없다.
< Generative model >
- requires enough data to represent real distribution
- requires enough train time
Discriminative model : 데이터양이 많지않을경우 패턴파악, 레이블링 쉬워서 이용됨
샘플된 데이터로는 왜곡된 판단이 이루어질 수가 있음 (한정된 데이터에 과적합될 수 있음)
- ex. 타이타닉호 인적정보 이용 > 구조되었는지 아닌지
- Generative Training
- All you need is just training power and time
Pre-Trained LM
GPT is not just a language model
Unsupervised pre-training
A multi-layer Transformer decoder is used for this language model
- Natural Language Inference
- Question Answering
- Semantic Similarity
- Classification
성능 굿
- 핵심
- language model 학습방법, 엄청나게 많은 txt를 통해서 NLP 처리 능력이 뛰어난 모델을 만드는것
기존 NLP처리 모델을 fine-tuning할 경우 transfer learning 을 통해서 별도의 타스크 관련 딥러닝 모델을 추가적으로 연결해야함
However, gpt는 딥러닝 추가 필요없이 fine-tuning 가능
모델이 이미 자연어처리능력이 뛰어남
GPT1 has 2 steps of GPT train
[1] 비지도, Pre-Training
[2] 지도, Fine Tuning
- 단순히 데이터만 바꾸어서 진행됨
왜 GPT가 트랜스포머의 Decoder를 메인으로 삼았는가?
트랜스포머가 기계번역에 초점을 맞춘반면에 GPT1은 4가지 태스크에 아주 놀라운 성능을 보여줬음
- (1) Natural Language Inference
2 문장이 주어졌을 때, 2문장의 관계를 유추하는 딥러닝 모델
( A문장이 참일경우에 B문장이 반드시 참일 경우 > Entailment,
두문장이 모순될경우 Contradiction)
- Entailment needs 2 sentences but if we put in GPT model, it is considered as just a sentence.
- how could this be possible?
- 2문장 사이에 Special Char(delimeter)를 집어넣고 input layer에 하나로 넣음
- (2) Question Answering
- 딥러닝모델에 질문과 함께 관련된 정보를 준 후에, 딥러닝모델이 관련정보에서 정답을 제대로 찾는지 테스트
- (3) Semantic Similarity
- 두문장이 비슷한지아닌지 테스트
- (4) Classification
- 주어진 문장이 이미 정의한 어떤 그룹으로 분류하는 테스트
GPT1 has 2 types of learning
(1) 방대한양의 데이터가 없는 텍스트를 사용해서 랭귀지 모델로의 학습 진행 (비지도)(Pre-training)
Unsupervised Learning with unlabeled enormous text data
(2) 각각의 자연어처리 문제에 따른 레이블이 있는 데이터로 Fine -Tuning 진행 (지도)
Supervised Fine tuning on each specific task
각 pretrained model에 linear layer를 추가
The inputs are passed through the pre-trained model to obtain the final transformer block’s activation hm, which is then fed into an added linear output layer with paramer w to predict y.
Comparison between trend before GPT1 and after.
Trend before GPT
기존모델은 fine tuning을 위해 추가적인 레이어 필요 (significant amount of task specific customization)
GPT1은 추가레이어필요없음.
Language model 학습시에 이미 상당한 자연어처리능력을 가주었기때문에 조금의 fine tuning data로도 모델 변경없이 더 나은 성능.
다양한 형태의 입력값을 하나의 입력값으로 치환해서 입력하는것도 impressive!
기존 딥러닝 모델들 (word-embedding, character embedding) 의 임베딩 방법보다 진화된방법(byte-pair encoding ) 이용
- *byte-pair encoding
자주 함께 사용되는 캐릭터를 하나의 묶음으로 사용, word, char embedding의 장점을 가지고있음
word embedding ( trained on unlabeled corpora) :
단어간의 유사도를 가지고있음, 학습시에 보지못했던 단어는 단순히 유사도가 전혀없는 zero-vector로 처리되기떄문에 신조어, 오탈자등에 약함character-embedding :
단어는 일정한 양의 캐릭터로 구성된 집합이기 때문에 zero-vector가 나올확률이 거의없지만 단어간의 유사도는 word embedding보다 낮음
ex) Hackable deep learning
- word embedding에서는 zero-vector가 될 확률이 큼
- byte-pair embedding 에서는
hack,able로 분리해서 의미 간직, word,char embedding보다 입력값의 의미를 더 잘 전달했기 때문에 더 나은 모델 성능 기대가능
Architecture
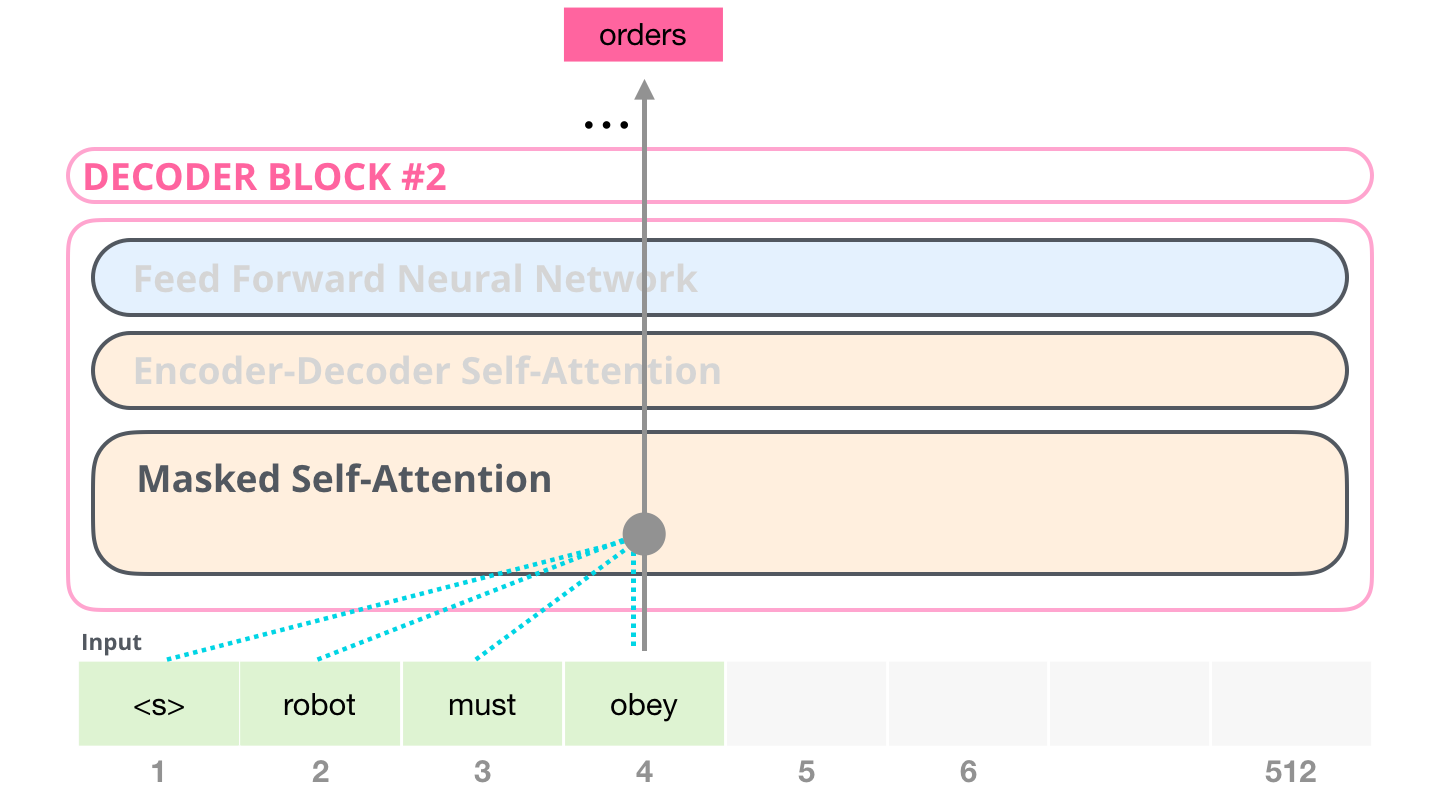
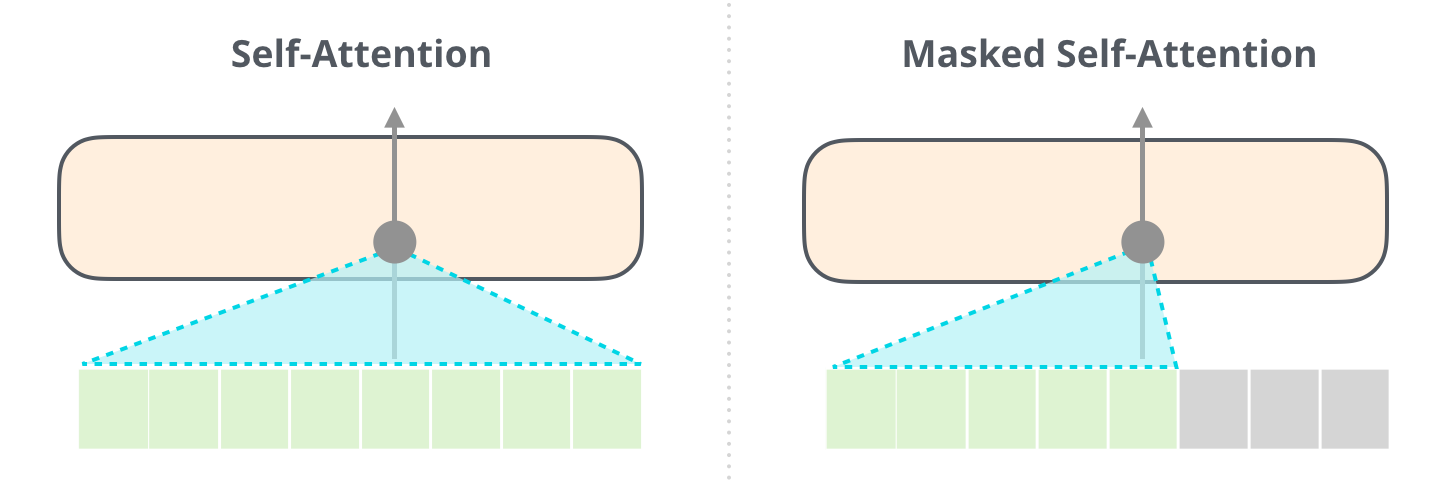
^ Decoder’s masked self-attention 이용
- 기존 트랜스포머 : Encoder-Decoder Self-Attention 있음 여긴 없음
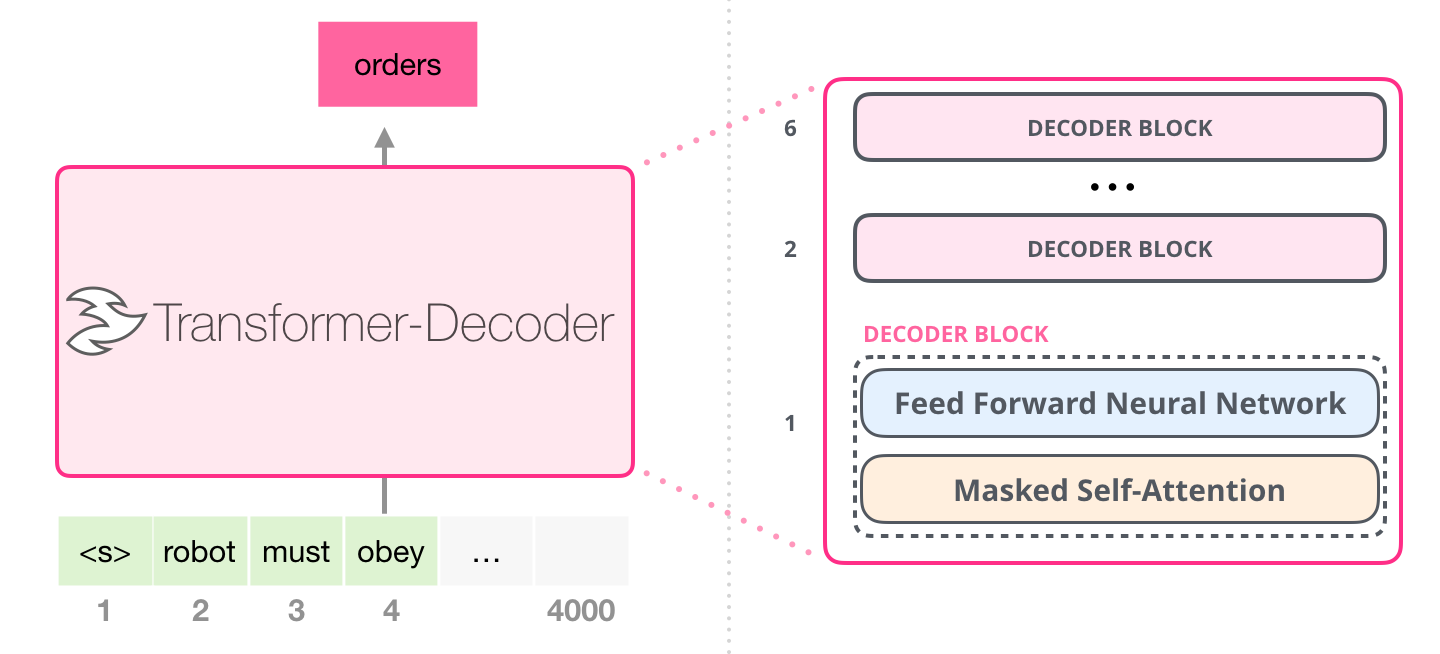
Decoder 를 몇개를 쌓을지는 hyper parameter로 지정
[ Evaluation task ]
Finetuned Transformer LM = GPT
GPT 성능 체크 > 4가지 태스크로 나누어 평가
기존의 SOTA 모형들보다 우리 모형이 더 잘한다.
하지만 몇개 데이터에 대해서는 성능이 낮은 부분이 있다 » ( 양이 적은 데이터..!)
1. Natural Language Inference (NLI)(Entailment)
두문장간의 관계 파악. Judgment로 표현 (label은 3개 : 분류contradiction, neutral, entailment)
2문장 사이에 Special Char(delimeter)를 집어넣고 input layer에 하나로 넣음
2. Semantic Similarity
주어진 두문장간에 슌서를 바꿔서 넣고 a,b / b,a 넣고 컨캣을 해서 트랜스포머, 리니어 태워서 유사한 정도 점수로 계산.
3. Classification (긍/부 구분)
- simple text input > transformer 의 hidden state만을 이용해서 선형결합
- CoLA dataset : 문법적으로 맞았는지 틀렸는지 분류
- Stanford Sentiment Treebank-2 dataset : 문장의 sentiment 분류
4. Question Answering (Multiple Choice)
- 딥러닝모델에 질문과 함께 관련된 정보를 준 후에, 딥러닝모델이 관련정보에서 정답을 제대로 찾는지 테스트
[ Experiment ]
GPT 모델의 성능을 실험적으로 평가
pre-training : Book corpus 이용
supervised learning에 대한 데이터셋
- Layer 개수 증가함에 따라 정확도 향상, but layer12이후부터는 수렴 양상 보임
- Transformer vs LSTM
- Transformer > LSTM
Model Performance on different tasks
(4가지 태스크에 대한 데이터셋)
transformer의 pretraining유무, finetuning 유무에 따른 각 데이터셋의 스코어 비교
CoLA, SST2 : Classification
MRPC, STSB, QQP : Semantic Similarity
MNLI, QNLI : Natural Language Inference
트랜스포머의 디코딩블럭을 몇개나 쌓아야할까??
최대 12개까지 쌓았을 때 점점 성능이 올라감
Fine-tuning을 하면 성능이 올라감
- Pretraining 과정 無 : 성능 15% 하락
- 데이터셋이 크면 fine tuning 목적함수를 쓰는게 도움이된다. dataset이 더 적을땐 차라리 finetuning을 하지않는게 더 낫겠다.
- Finetuning (aux) 데이터셋이 클 경우에 더 효과적임.
- LSTM 은 오직 한 데이터셋에 대해서만 좋은 성능을 보였다. (RTE)
각주 및 추천자료
The Illustrated GPT-2 (Visualizing Transformer Language Models)