
Policy Knowledge Graph Construction from Korean Development Reports Using BERT and R-BERT
NLP
Named Entity Recognition (NER)
Relation Extraction (RE)
Knowledge Graph
Neo4j
Design
Developed an NLP pipeline that automatically extracts entities and relations from Korean development policy reports (e.g. Korean Economic Development History, KSP reports) and builds a structured, searchable knowledge graph using Neo4j.
The project aimed to improve the usability of government reports and enable policy analysts to trace entities, institutions, and policies over time.
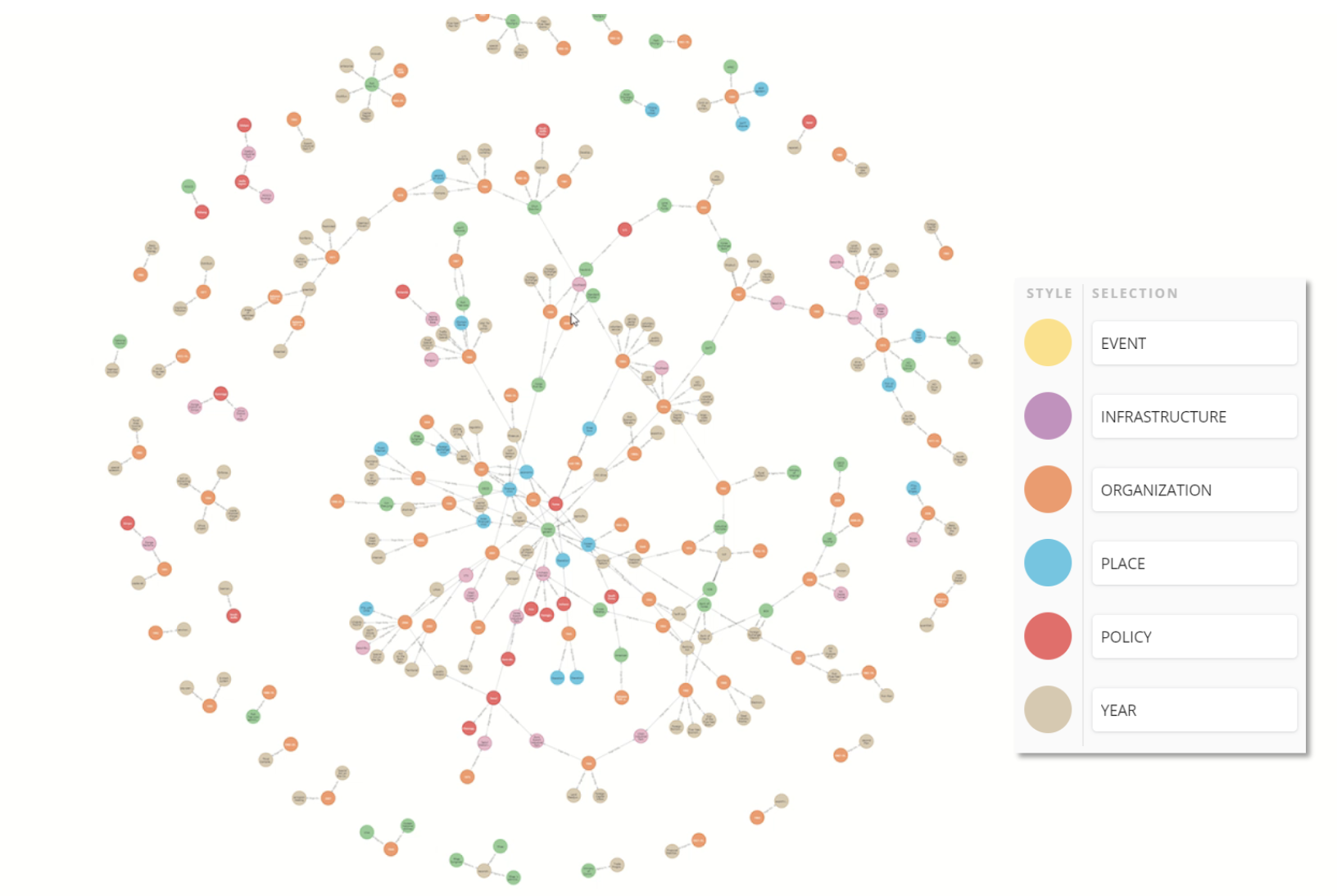
Data & Preprocessing
- Documents:
- Korean Economic Development History (331 pages)
- 137 Modularization Reports
- 19 KSP Policy Advisory Reports
- Additional data: SCOPUS abstract API used to supplement rare tag categories
- Preprocessing techniques:
- PDF to text using Apache Tika
- Coreference resolution using Stanford CoreNLP (ML-based model)
- Manual BIO2 tagging using TextAE for NER and relation tagging
- Filtering out inconsistent terminology or extremely rare entity types for model stability
Main Models & Techniques
Named Entity Recognition (NER)
- Model: BERT + CRF
- Tagging: BIO2 scheme
- Entity types: Institution, Region, Structure, Year, Policy, Event, Term (7 total)
- Achieved up to F1 score: 0.87 after tuning
- CRF enabled valid BIO structure learning (e.g. avoiding I-tags without B-prefix)
Relation Extraction (RE)
- Model: R-BERT (fine-tuned on custom dataset in Semeval-2010 task 8 format)
- Defined 9 relation types: e.g. Product-Producer, Cause-Effect, Entity-Origin (bidirectional)
- F1 score: 0.90 on test set
Knowledge Graph (KG)
- Database: Neo4j using py2neo
- Standardized relation directions for consistent KG structure
- Enforced uniqueness constraints on node names to avoid duplication
- Final output: 13,341 entities and 15,823 relations integrated into a live KG
Result
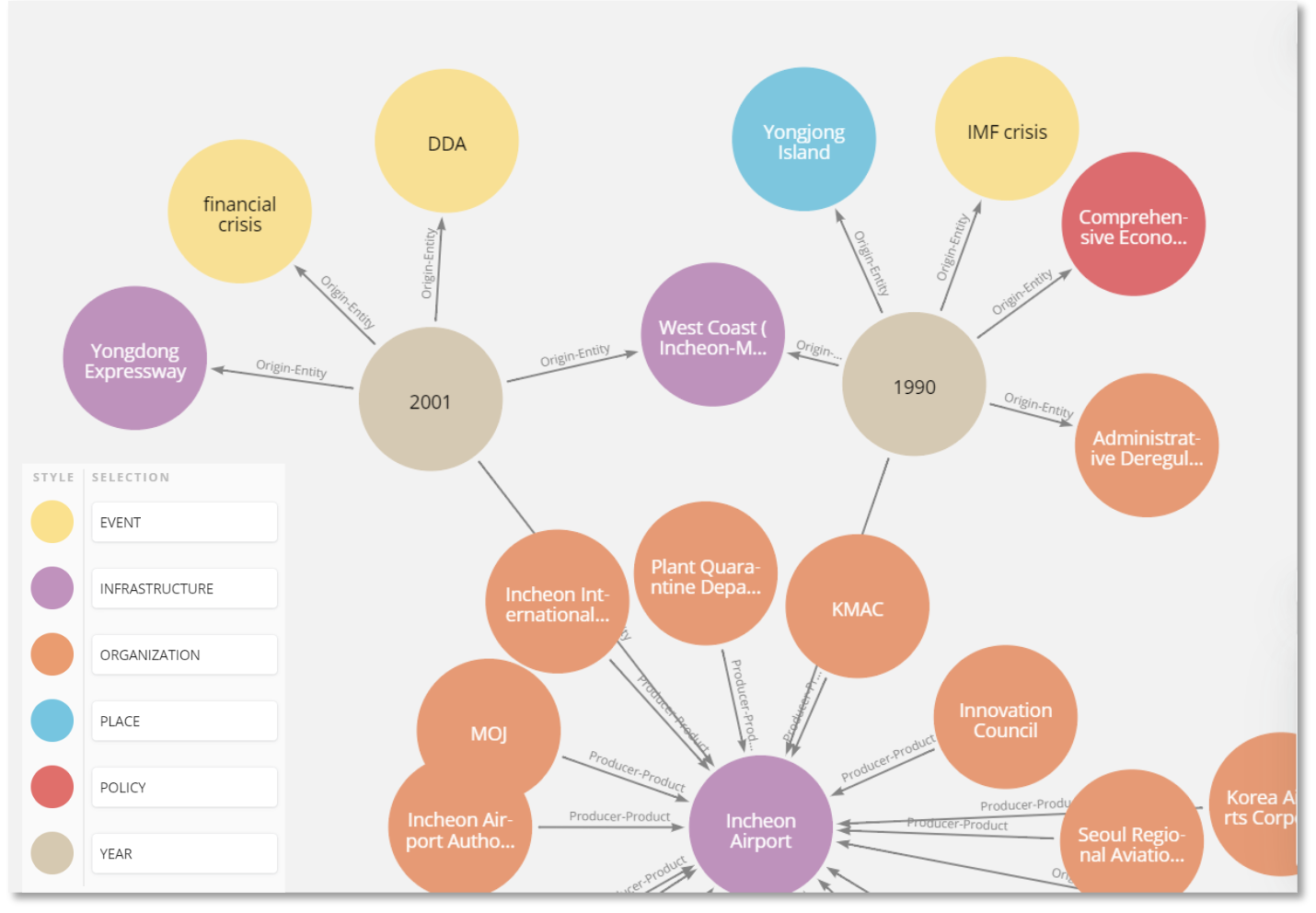
- Successfully constructed an interactive KG representing Korea’s development experiences
- Enabled entity-based queries (via Cypher) and visual exploration (via Neo4j Bloom)
- Example use cases:
- “Incheon Airport” node connects to institutions (e.g. MOLIT), events (e.g. IMF Crisis), and policies
- Entity timelines trace policy evolution by year or topic
- Used internally by KDI analysts for case study identification and cross-policy tracing
Challenges & Considerations
- Data sparsity in certain entity/relation classes; addressed with SCOPUS abstracts
- Inconsistent PDF formatting required manual parsing and filtering
- Ambiguity in defining domain-specific entity/relation types (e.g. “Term” vs “Policy”)
- Learned the importance of preprocessing and class balance through ablation testing
Team Collaboration
- Conducted in a team of 6 researchers, with subteams for NER, RE, and KG
- Led coordination and tracking through Slack and Notion (calendar, to-do DB, document embeds)
- Weekly meetings to align on progress and resolve modeling challenges
- Team structure (2 members per subtask) enabled parallel experimentation and fast iteration
Reflection
- This was my first hands-on application of NLP theory to a real-world document corpus
- Reinforced the importance of preprocessing and annotation in applied NLP
- NER and RE can unlock scalable knowledge extraction from government documents
- Knowledge Graphs are powerful tools not just for search, but for surfacing hidden policy patterns
- I’m excited to explore their potential across other domains like healthcare or education